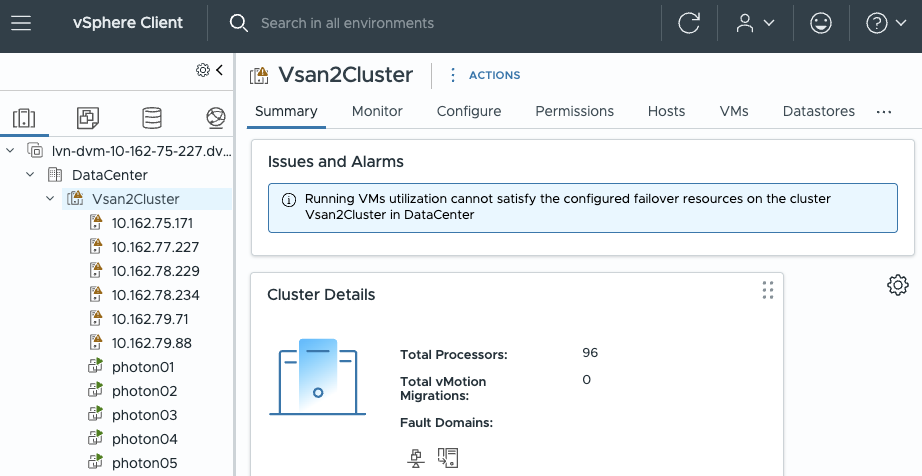
В настройках кластера VMware vSphere High Availability существует параметр Performance degradation VMs tolerate, который определяет допустимый уровень снижения производительности виртуальных машин при отказе одного из хостов кластера.
По умолчанию значение параметра установлено в 100%, что фактически означает отсутствие ограничений по деградации производительности в аварийном сценарии. При таком значении система не будет предупреждать администратора о возможном ухудшении SLA виртуальных машин после отказа узла.
Как работает параметр
Механизм оценивает, смогут ли уже запущенные виртуальные машины сохранить сопоставимый объем вычислительных ресурсов после отказа одного хоста. Логика работы следующая:
Рассматривается сценарий отказа одного узла кластера.
Оценивается суммарная доступная вычислительная емкость после отказа.
С помощью VMware Distributed Resource Scheduler DRS моделируется перераспределение работающих виртуальных машин на другие хосты ESX.
Проверяется, какой уровень снижения ресурсов (CPU / Memory) получат виртуальные машины.
Если ожидаемая деградация превышает заданный порог, генерируется предупреждение.
Важно! Это не блокирующий механизм. Даже при появлении предупреждения запуск новых виртуальных машин остается возможным - параметр выполняет исключительно функцию оповещения.
Требования для работы
Для корректной работы параметра необходим работающий DRS, но включенный Admission Control не требуется. Это частое заблуждение: параметр не использует настройки Admission Control (например, Host failures cluster tolerates). Вместо этого он самостоятельно моделирует отказ одного хоста и анализирует последствия для производительности виртуальных машин.
Практический смысл настройки
Параметр полезен в сценариях, когда:
В кластере высокая консолидация нагрузки.
Виртуальные машины активно используют CPU / RAM выше уровня reservation.
Ресурсы после отказа хоста могут оказаться достаточными для запуска ВМ, но недостаточными для сохранения нужной производительности.
Пример:
Допустим, кластер работает с загрузкой 80–85%. После выхода одного узла из строя оставшиеся хосты смогут принять виртуальные машины, однако фактическая доступность ресурсов для каждой машины снизится.
50% — допускается существенное снижение производительности
100% — предупреждения фактически отключены
Рекомендации по настройке
Практически значение 100% малоинформативно, так как не дает сигналов о потенциальной проблеме.
Часто используются значения:
0–10% — для критичных production-нагрузок
25% — сбалансированный вариант
50% — для сред с менее строгими SLA
Выбор зависит от допустимого уровня деградации сервисов при аварийном восстановлении.
Вывод
Параметр Performance degradation VMs tolerate — это механизм оценки риска снижения производительности ВМ при отказе узла, а не механизм резервирования ресурсов.
Его особенности:
Анализирует сценарий отказа одного хоста
Требует DRS
Не зависит от Admission Control
Не запрещает запуск ВМ
Предупреждает о возможном ухудшении производительности
Настройка позволяет заранее понять, насколько кластер готов к отказу оборудования с точки зрения SLA, а не только с точки зрения возможности перезапуска виртуальных машин.
Технология Advanced Memory Tiering в VMware Cloud Foundation 9 позволяет существенно расширить эффективный объём памяти хоста за счёт NVMe-накопителей — без изменения рабочих процессов и без влияния на привычные инструменты управления. Ниже собраны практические рекомендации, которые помогут правильно оценить среду, корректно настроить платформу и избежать типичных ошибок при развёртывании.
Как работает двухуровневая память
Архитектура Advanced Memory Tiering строится на двух уровнях.
Tier 0 — это DRAM: быстрая оперативная память, которая обслуживает активные страницы виртуальных машин.
Tier 1 — NVMe-накопитель, куда перемещаются холодные, редко используемые страницы. При этом память гипервизора (vmkernel) никогда не попадает в NVMe: ESX всегда работает исключительно в DRAM.
Когда виртуальная машина обращается к странице, находящейся в Tier 1, гипервизор возвращает её в DRAM — прозрачно и без участия гостевой ОС. Такая схема идеально подходит для рабочих нагрузок с выраженным разделением горячих и холодных страниц памяти.
Оценка готовности среды
Прежде чем включать Memory Tiering, необходимо проанализировать текущее потребление памяти. Ключевой показатель — активная память (active memory): объём страниц, к которым виртуальные машины реально обращаются в единицу времени. Технология оптимально работает, когда потреблённая (allocated) память превышает 50% от установленного объёма DRAM, а активная остаётся ниже этого порога.
Проверить активную память можно несколькими способами. В интерфейсе vCenter откройте VM > Monitor > Performance > Advanced, переключитесь в режим отображения памяти и выберите режим реального времени — показатель active memory доступен только в нём, поскольку относится к статистике уровня 1.
Для более широкого охвата подойдёт VCF Operations — если он уже развёрнут в инфраструктуре, он обеспечит сквозную видимость по всем хостам и кластерам. Ещё один вариант — RVTools: утилита собирает статистику памяти в реальном времени и позволяет быстро оценить картину по всей среде.
Порог активной памяти: правило 50%
Главное эксплуатационное правило Memory Tiering звучит просто: активная память должна оставаться на уровне 50% или ниже от объёма DRAM. Это гарантирует, что горячий рабочий набор данных комфортно размещается в быстрой памяти и при этом остаётся достаточный запас.
Если активная память стабильно превышает 70% от объёма DRAM, часть горячих страниц неизбежно окажется в Tier 1, и производительность виртуальных машин может заметно снизиться. В такой ситуации следует либо добавить DRAM на хост, либо перераспределить нагрузку между узлами кластера, прежде чем включать тиринг.
Настройка соотношения DRAM:NVMe
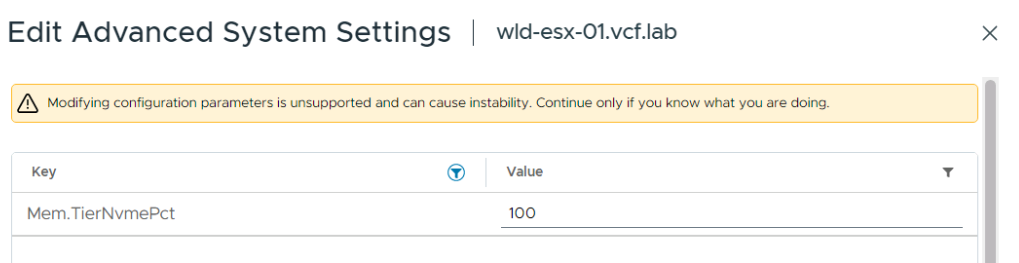
При включении Memory Tiering ESXi устанавливает соотношение DRAM к NVMe равным 1:1 по умолчанию. Это означает, что при наличии 512 ГБ DRAM хост получит дополнительные 512 ГБ ёмкости Tier 1. Параметр контролируется через расширенную настройку хоста: Mem.TierNVMePct со значением по умолчанию 100 (100% от объёма DRAM).
Рекомендуется сохранять соотношение 1:1 для большинства рабочих нагрузок — оно охватывает типичные сценарии использования. Изменять его стоит только после тщательного анализа профиля активной памяти конкретных ВМ. При выборе размера NVMe-накопителей разумно ориентироваться с запасом: более ёмкие устройства замедляют износ ячеек, дают пространство для будущего изменения соотношения и позволяют безболезненно справляться с неожиданным ростом нагрузки.
Подходящие рабочие нагрузки
Memory Tiering наиболее эффективна для рабочих нагрузок с естественным разделением горячих и холодных страниц. В их числе:
Общая серверная виртуализация — разнородный парк ВМ с умеренной и переменной активностью памяти.
VDI-среды — виртуальные рабочие столы с большим количеством ВМ, каждая из которых использует лишь часть выделенной памяти одновременно.
Среды разработки и тестирования — временные ВМ, которые редко используют всю выделенную память одновременно.
Веб-серверы и серверы приложений — нагрузки с предсказуемым рабочим набором в памяти.
Базы данных с умеренной активностью — СУБД, у которых значительная часть данных в памяти остаётся холодной
Неподходящие рабочие нагрузки
Ряд профилей виртуальных машин в настоящее время не поддерживает работу с Memory Tiering. Для таких ВМ тиринг следует отключить на уровне виртуальной машины — это принудительно размещает все её страницы в Tier 0 (DRAM).
Высокопроизводительные и latency-sensitive ВМ — приложения, требующие предсказуемых ультранизких задержек доступа к памяти
ВМ с аппаратной защитой памяти — виртуальные машины, использующие технологии шифрования AMD SEV, Intel SGX или Intel TDX
ВМ с Fault Tolerance (FT) — непрерывная синхронизация состояния несовместима с тирингом
«Монстроидальные» ВМ — машины с объёмом памяти от 1 ТБ и более 128 vCPU
ВМ с большими страницами памяти (large memory pages)
Вложенная виртуализация (nested VMs)
Если в кластере присутствуют такие нагрузки, оптимальная стратегия — выделить для них отдельные хосты и включить Memory Tiering только на оставшихся узлах кластера, либо управлять исключениями на уровне отдельных ВМ.
Интеграция с vSphere
Advanced Memory Tiering полностью интегрирована в стандартные механизмы управления vSphere — никаких специальных процедур не требуется:
vMotion — миграция ВМ между хостами работает прозрачно; оба уровня памяти учитываются при переносе.
DRS — балансировщик нагрузки осведомлён об обоих уровнях и учитывает их при принятии решений о размещении ВМ.
High Availability (HA) — при отказе хоста ВМ перезапускаются на оставшихся узлах по стандартным правилам HA.
Рекомендации по развёртыванию
Для успешного внедрения рекомендуется придерживаться следующих принципов. Во-первых, поддерживайте единую конфигурацию хостов в кластере с помощью vSphere Configuration Profiles — это исключает расхождения между узлами и упрощает масштабирование. Во-вторых, применяйте поэтапный подход: включайте тиринг последовательно, начиная с одного-двух хостов, оценивайте результаты и только потом распространяйте изменение на весь кластер. В-третьих, фиксируйте исключения: документируйте все ВМ, для которых Memory Tiering отключена на уровне виртуальной машины, чтобы не потерять контроль над конфигурацией при росте инфраструктуры.
Мониторинг после включения
После включения Memory Tiering следует регулярно отслеживать ключевые показатели:
Процент активной памяти на уровне хостов и кластера
Паттерны доступа к страницам (горячие/холодные)
Тренды утилизации памяти по кластеру в целом
Потребление памяти на уровне отдельных ВМ
Задержки чтения и записи NVMe-накопителей Tier 1
Рост задержек NVMe или увеличение активной памяти выше порога 50% DRAM — сигнал для пересмотра распределения нагрузки или конфигурации тиринга. Регулярный мониторинг позволяет выявлять изменения в профиле нагрузки на ранней стадии и реагировать проактивно.
VMware недавно опубликовала обновлённый набор технических руководств, которые приводят рекомендации в соответствие с архитектурой эпохи VMware Cloud Foundation
и с новыми возможностями приложений Microsoft, включая SQL Server 2025 и Windows Server 2025.
Если вы планируете развёртывание VCF, модернизируете существующие среды, стандартизируете платформу, обновляете парк SQL Server или модернизируете инфраструктуру идентификации, мы рекомендуем ознакомиться с этими документами до того, как будет окончательно утверждён ваш следующий дизайн-воркшоп, цикл закупок или план миграции.
Руководство 1: Проектирование Microsoft SQL Server на VMware Cloud Foundation
Для многих команд решение о виртуализации SQL Server уже принято. Как говорится в руководстве: «вопрос больше не в том, виртуализировать ли SQL Server, а в том, как…». И это «как» существенно изменилось в мире VCF. Платформа стала более регламентированной, операционная модель — более стандартизированной, а поддерживающие возможности (хранилище, сеть, управление жизненным циклом, безопасность) эволюционировали с учётом развития аппаратных возможностей и операционных методик.
Обновлённое руководство предназначено для читателей, которые уже понимают как VCF, так и SQL Server. Оно ориентировано на несколько ролей: архитекторов, инженеров/администраторов и DBA.
Несколько моментов, на которые стоит обратить внимание:
Современные рекомендации по CPU и NUMA теперь учитывают и новое поведение топологии в эпоху VCF. Руководство рассматривает «новые параметры конфигурации топологии vNUMA в VMware Cloud Foundation (VCF)» и объясняет, почему это поведение важно для крупных виртуальных машин SQL Server.
Чёткая и обновлённая позиция по CPU hot plug в эпоху SQL Server 2025. В руководстве прямо указано: CPU Hot-Add больше не поддерживается в SQL Server 2025, и его не следует включать на таких виртуальных машинах.
Рекомендации по хранилищу, соответствующие направлению развития VCF. Если вы оцениваете архитектурные варианты vSAN, руководство объясняет, почему vSAN Express Storage Architecture (ESA) привлекателен для заказчиков, переходящих на более современное оборудование, и подчёркивает возможности эффективности ESA, такие как глобальная дедупликация и преимущества сжатия для нагрузок баз данных.
Пояснения по устаревающим функциям, влияющим на долгоживущие архитектуры. Если в вашей текущей архитектуре активно используются vVols, учтите, что Virtual Volumes объявлены устаревшими, начиная с VCF 9.0 и VMware vSphere Foundation 9.0 (полный отказ запланирован в будущих релизах).
Операционная реалистичность для мобильности и обслуживания. Руководство рассматривает использование multi-NIC vMotion для снижения риска зависания (stun) при миграции крупных, потребляющих много памяти виртуальных машин SQL, а также отмечает, что VCF внедряет vMotion Notifications, чтобы помочь чувствительным к задержкам и кластер-осведомлённым приложениям безопаснее обрабатывать миграции.
Если вы принимаете решения - это тот документ, который снижает объём переработок, вызванных неожиданностями. Если вы технический специалист - это тот документ, который не позволит вам унаследовать архитектуру в стиле «it depends», которая позже приведёт к простою.
Руководство 2: Проектирование Microsoft SQL Server для высокой доступности на VMware Cloud Foundation
Второе руководство сосредоточено там, где ставки особенно высоки: корректное проектирование доступности SQL Server на VCF без смешивания устаревших предположений, неподдерживаемых конфигураций или подхода «потом исправим» в кластеризации.
Оно написано для смешанной аудитории, включая DBA, администраторов VMware, архитекторов и IT-руководителей. И в нём ясно указано, что «доступность» — это не функция, которую добавляют в конце; выбранная модель защиты должна определяться бизнес-требованиями.
Несколько особенно практичных обновлений:
Реалии доступности SQL Server 2025, чётко сопоставленные с механизмами защиты. Руководство связывает уровни защиты с современными возможностями обеспечения доступности SQL Server, подчёркивает области, где SQL Server 2025 усиливает архитектуры на базе Availability Groups (AG), и отмечает, что Database Mirroring удалён в SQL Server 2025.
Рекомендации по согласованию жизненного цикла, которые действительно важны для IT-руководства. Начиная с SQL Server 2025, отмечается, что более старые версии Windows Server вышли из основной поддержки, и рекомендуется использовать Windows Server 2025 или Windows Server 2022 при наличии совместимости — прямой переход к поддерживаемым и обоснованным платформам.
Современные варианты кластеризации с общими дисками без навязывания устаревших архитектур. Руководство указывает, что в средах эпохи VCF 9 семантика общих дисков для FCI может быть реализована современными способами — подчёркивается использование Clustered VMDKs и явно обозначается движение в сторону отказа от устаревших зависимостей.
Рекомендации по DRS anti-affinity, предотвращающие «самоорганизованные» события HA. Если узлы кластера SQL работают на одном и том же хосте ESXi «потому что так решил DRS», это не высокая доступность, а отложенный инцидент. Настройте соответствующие правила DRS, чтобы узлы кластера были физически разделены.
Требования к vMotion Application Notification, изложенные подробно. Руководство описывает использование уведомлений приложений, включая требования, такие как актуальные VMware Tools и рекомендуемая настройка таймаутов — именно те детали, которые команды часто выясняют в условиях уже упавшей системы.
Рекомендации по vSAN ESA, отражающие текущие возможности. Указывается направление политик ESA и отмечается глобальная дедупликация (впервые представленная в VCF 9.0) как рекомендуемая для определённых сценариев Availability Group SQL Server в пределах одного кластера vSAN.
Это то руководство, которое вы передаёте команде, когда бизнес говорит: «нам нужна более высокая доступность», — и вы хотите, чтобы ответом стало инженерно проработанное решение.
Руководство 3: Виртуализация служб домена Active Directory на VMware Cloud Foundation
Active Directory (AD) Domain Services (DS) — одна из тех служб, о которых не думают до тех пор, пока всё не перестанет работать. Обновлённое руководство по AD DS прямо признаёт это, указывая, что многие организации справедливо рассматривают AD DS как по-настоящему критичное для бизнеса приложение, поскольку аутентификация, доступ к ресурсам и бесчисленные рабочие процессы зависят от него.
Оно также напрямую обращается к сохраняющемуся рефлексу «физического контроллера домена». Благодаря развитию Windows Server и зрелым практикам VCF, в руководстве говорится, что эти улучшения теперь позволяют организациям «безопасно виртуализировать сто процентов своей инфраструктуры AD DS».
Существенно обновлены не общие рекомендации «виртуализируйте это», а современный набор функций и механизмов защиты, которые меняют подход к проектированию и защите виртуальных контроллеров домена:
В руководстве указано, что лишь несколько усовершенствований существенно изменяют прежние рекомендации, включая Virtualization-Based Security (VBS), Secure Boot, шифрование на уровне виртуальной машины и улучшенную синхронизацию времени в гостевых ВМ — и эти изменения учтены там, где это необходимо.
Документ явно ориентирован на несколько аудиторий (архитекторов, инженеров/администраторов и руководителей/владельцев процессов), что важно для AD DS, поскольку проектирование и эксплуатация неразделимы.
Подчёркиваются операционные меры защиты при восстановлении после сбоев. Например, рекомендуется использовать приоритет перезапуска ВМ в vSphere HA, чтобы ключевые инфраструктурные службы запускались раньше после аварийного восстановления.
Подробно рассматриваются механизмы обеспечения целостности в эпоху виртуализации (например, поведение VM-Generation ID), созданные специально для устранения исторических опасений, связанных со снапшотами и откатами.
Если вы модернизируете инфраструктуру идентификации, консолидируете датацентры или строите частное облако на базе VCF с сильной позицией по безопасности, этот документ обязателен к прочтению. AD DS — это не просто ещё одна рабочая нагрузка. Это сущность, от которой зависит работа всего вашего стека.
Руководство 4: Запуск Microsoft SQL Server Failover Cluster Instance на VMware vSAN платформы VMware Cloud Foundation 9
Если ваша модель обеспечения доступности по-прежнему основана на кластеризации с общими дисками — будь то из-за ограничений приложений, операционных предпочтений или необходимости сохранить модель SQL Server FCI — это руководство является практическим дополнением «как это реально работает на VCF 9» к более общим рекомендациям по HA. Это эталонная архитектура для запуска Microsoft SQL Server Failover Cluster Instance (FCI) с использованием общих дисков на базе vSAN, валидированная как для стандартного кластера vSAN, так и для сценария растянутого кластера vSAN.
Несколько моментов, на которые стоит обратить внимание:
Нативная поддержка WSFC + общих дисков на vSAN (с подробным описанием механики). В VCF 9 «vSAN обеспечивает нативную поддержку виртуализированных Windows Server Failover Clusters (WSFC)» и «поддерживает SCSI-3 Persistent Reservations (SCSI3PR) на уровне виртуального диска» — ключевое требование для арбитража общих дисков в WSFC.
Две настройки конфигурации, от которых зависит работоспособность общих дисков. Указывается, что общие диски должны быть подключены к контроллеру с параметром SCSI Bus Sharing, установленным в Physical, и что «режим диска для всех дисков в кластере должен быть установлен в Independent – Persistent», чтобы избежать неподдерживаемой семантики снапшотов на общих дисках.
Операционные особенности растянутого кластера: задержки, размещение и кворум являются частью архитектуры. Рекомендуется «менее четырёх миллисекунд межсайтовой (round trip) задержки» для SQL-баз данных уровня tier-1 в растянутых кластерах vSAN, а также подчёркивается необходимость правил DRS VM/Host для разделения узлов WSFC по разным хостам.
Также рекомендуется использовать диск-свидетель кворума, чтобы растянутый кластер сохранял доступность witness-диска при отказе сайта без остановки службы кластера FCI.
Практический путь миграции с SAN pRDM на общие VMDK vSAN. С самого начала подчёркивается: «перед миграцией настоятельно рекомендуется создать резервную копию», и отмечается, что миграция выполняется офлайн. Описываются шаги по остановке роли кластера, выключению узлов и использованию Storage Migration для преобразования pRDM в VMDK на vSAN ± с обходным решением через PowerCLI (включая пример кода) в случае, если выбор формата диска в мастере Migrate недоступен.
Это руководство, которое вы передаёте команде, когда требование звучит как «нам нужна семантика FCI», и вы хотите получить осознанную, поддерживаемую архитектуру.
Что дальше
Если вы активно проектируете, обновляете или мигрируете инфраструктуру, рассматривайте эти руководства в контексте команд:
Команды платформы: сначала прочитайте руководство по SQL Server, чтобы согласовать значения по умолчанию вычислений/хранилища/сети с поведением SQL.
DBA и инженеры инфраструктуры: прочитайте руководство по HA до того, как зафиксируете модель кластеризации, стратегию хранения и модель обслуживания.
Команды по идентификации и безопасности: прочитайте руководство по AD DS, чтобы согласовать меры настройки, восстановления и операционные процессы с современными механизмами защиты виртуализации.
Команды, использующие (или стандартизирующие) SQL Server FCI: прочитайте руководство по FCI на vSAN, чтобы зафиксировать требования к общим дискам, позицию по политике хранения и ограничения растянутого кластера до внедрения.
Ниже приведены прямые ссылки для скачивания упомянутых документов:
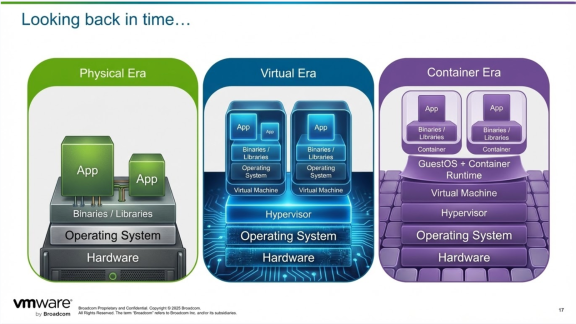
Виртуализация решила основную проблему «один сервер — одно приложение». Контейнеризация опиралась на этот результат и уточнила способ его достижения. Однако виртуализация остаётся основой современной вычислительной среды, и многие из наиболее критически важных рабочих нагрузок в мире продолжают и будут продолжать работать в виртуальных машинах. Помимо своей долговечности, виртуализация улучшает контейнеризацию и Kubernetes, помогая обеспечивать ключевые результаты, которых ожидают пользователи и которые требуются бизнесу.
Администраторы ИТ-инфраструктур и ИТ-менеджеры часто задают вопросы наподобие: «Какое отношение виртуализация имеет к Kubernetes?» Понимание этого крайне важно для ИТ-подразделений и организационных бюджетов. Вычисления революционизировали то, как мы взаимодействуем друг с другом, как работаем, и сформировали рамки возможного в промышленности. ИТ-нагрузки требуют вычислительных ресурсов, таких как CPU, память, хранилище, сеть и т. д., чтобы выполнять нужные функции — например, отправку электронного письма или обновление базы данных. Важная часть бизнес-операций заключается в том, чтобы ИТ-организации оптимизировали стратегию размещения своих нагрузок — будь то на мейнфрейме, в локальном дата-центре или в публичном облаке.
Виртуализация не исчезла с появлением Kubernetes — напротив, она помогает Kubernetes работать лучше в масштабе предприятия.
Виртуализация
С зарождения электронной вычислительной техники в 1940-х годах пользователи взаимодействовали с выделенным физическим оборудованием для выполнения своих задач. Приложения, рабочие нагрузки и оборудование стремительно развивались и расширяли возможности, сложность и охват того, что пользователи могли делать с помощью вычислений. Однако оставалось ключевое ограничение — одна машина, или сервер, выделялась под одно приложение. Например, у организаций были серверы, выделенные под почтовую функциональность, или целый сервер, выделенный под действия, выполнявшиеся лишь несколько раз в месяц, такие как начисление заработной платы.
Виртуализация — использование технологий для имитации ИТ-ресурсов — была впервые реализована в 1960-х годах на мейнфреймах. В ту эпоху виртуализация обеспечивала совместный доступ к ресурсам мейнфрейма и позволяла использовать мейнфреймы для нескольких приложений и сценариев. Это стало прообразом современной виртуализации и облачных вычислений, позволяя нескольким приложениям работать на выделенном оборудовании.
VMware возглавила бум облачных вычислений благодаря виртуализации архитектуры x86 — самого распространённого набора инструкций для персональных компьютеров и серверов. Теперь физическое оборудование могло размещать несколько распределённых приложений, поддерживать многих пользователей и полностью использовать дорогостоящее «железо». Виртуализация — ключевая технология, которая делает возможными публичные облачные вычисления; ниже приведено резюме:
Абстракция: виртуализация абстрагирует физическое оборудование, предоставляющее CPU, RAM и хранилище, в логические разделы, которыми можно управлять независимо.
Гибкость, масштабируемость, эластичность: абстрагированные разделы теперь можно масштабировать под потребности бизнеса, выделять и отключать по требованию, а ресурсы - возвращать по мере необходимости.
Консолидация ресурсов и эффективность: физическое оборудование теперь может запускать несколько логических разделов «правильного размера» с нужным объёмом CPU, RAM и хранилища — максимально используя оборудование и снижая постоянные затраты, такие как недвижимость и электроэнергия.
Изоляция и безопасность: у каждой ВМ есть собственный «мир» с ОС, независимой от той, что запущена на физическом оборудовании, что обеспечивает глубокую безопасность и изоляцию для приложений, использующих общий хост.
Для большинства предприятий и организаций критически важные рабочие нагрузки, обеспечивающие их миссию, рассчитаны на работу в виртуальных машинах, и они доверяют Broadcom предоставлять лучшие ВМ и лучшие технологии виртуализации. Доказав, что инфраструктуру можно абстрагировать и управлять ею независимо от физического оборудования, виртуализация заложила основу для следующей эволюции размещения рабочих нагрузок.
Контейнеризация
По мере роста вычислительных потребностей экспоненциально росла и сложность приложений и рабочих нагрузок. Приложения, которые традиционно проектировались и управлялись как монолиты, то есть как единый блок, начали разбиваться на меньшие функциональные единицы, называемые микросервисами. Это позволило разработчикам и администраторам приложений управлять компонентами независимо, упрощая масштабирование, обновления и повышая надёжность. Эти микросервисы запускаются в контейнерах, которые стали популярны в отрасли благодаря Docker.
Контейнеры Docker упаковывают приложения и их зависимости - такие как код, библиотеки и конфигурационные файлы - в единицы, которые могут стабильно работать на любой инфраструктуре: будь то ноутбук разработчика, сервер в датацентре предприятия или сервер в публичном облаке. Контейнеры получили своё название по аналогии с грузовыми контейнерами и дают многие из тех же преимуществ, что и их физические «тёзки», такие как стандартизация, переносимость и инкапсуляция. Ниже — краткий обзор ключевых преимуществ контейнеризации:
Стандартизация: как грузовые контейнеры упаковывают товары в формат, с которым другое оборудование может взаимодействовать единообразно, так и программные контейнеры упаковывают приложения в унифицированную, логически абстрагированную и изолированную среду
Переносимость: грузовые контейнеры перемещаются с кораблей на грузовики и поезда. Программные контейнеры могут запускаться на ноутбуке разработчика, в средах разработки, на продакшн-серверах и между облачными провайдерами
Инкапсуляция: грузовые контейнеры содержат всё необходимое для выполнения заказа. Программные контейнеры содержат код приложения, среду выполнения, системные инструменты, библиотеки и любые другие зависимости, необходимые для запуска приложения.
Изоляция: и грузовые, и программные контейнеры изолируют своё содержимое от других контейнеров. Программные контейнеры используют общую ОС физической машины, но не зависимости приложений.
По мере того как контейнеры стали отраслевым стандартом, команды начали разрабатывать собственные инструменты для оркестрации и управления контейнерами в масштабе. Kubernetes появился из этих проектов в 2015 году, а затем был передан сообществу open source. Продолжая морскую тематику контейнеров, Kubernetes по-гречески означает «рулевой» или «пилот» и выполняет роль мозга инфраструктуры.
Контейнер позволяет легко развёртывать приложения - Kubernetes позволяет масштабировать число экземпляров приложения, он гарантирует, что каждый экземпляр остаётся запущенным, и работает одинаково у любого облачного провайдера или в любом датцентре. Это три «S»-столпа: самовосстановление (Self-Healing), масштабируемость (Scalability) и стандартизация (Standardization). Эти результаты ускорили рост Kubernetes до уровня отраслевого золотого стандарта, и он стал повсеместным в cloud native-вычислениях, обеспечивая операционную согласованность, снижение рисков и повышенную переносимость.
Виртуализация > Контейнеризация
Виртуализация проложила путь разработчикам к размещению и изоляции нескольких приложений на физическом оборудовании, администраторам — к управлению ИТ-ресурсами, отделёнными от базового оборудования, и доказала жизнеспособность абстрагирования нижних частей стека для запуска и масштабирования сложного ПО. Контейнеры развивают эти принципы и абстрагируют уровень приложений, предоставляя следующие преимущества по сравнению с виртуализацией:
Эффективность: благодаря общей ОС контейнеры устраняют накладные расходы (CPU, память, хранилище), связанные с запуском нескольких одинаковых ОС для приложений.
Скорость: меньший «вес» позволяет значительно быстрее запускать и останавливать.
Переносимость: контейнеры лёгкие и могут выполняться на любом совместимом контейнерном рантайме.
Виртуализация улучшает Kubernetes
Виртуализация также стабилизирует и ускоряет Kubernetes. Большинство управляемых Kubernetes-сервисов, включая предложения гиперскейлеров (EKS на AWS, AKS на Azure, GKE на GCP), запускают Kubernetes-слой поверх виртуализованной ОС. Поскольку Kubernetes-среды обычно сложны, виртуализация значительно усиливает изоляцию, безопасность и надёжность, а также упрощает операции управления накладными процессами. Краткий обзор преимуществ:
Изоляция и безопасность: без виртуализации все контейнеры, работающие в кластере Kubernetes на физическом хосте, используют один и тот же Kernel (ядро ОС). Если контейнер взломан, всё, что работает на физическом хосте, потенциально может быть скомпрометировано на уровне оборудования. Гипервизор препятствует распространению злоумышленников на другие узлы Kubernetes и контейнеры.
Надёжность: Kubernetes может перезапускать контейнеры, если те падают, но бессилен, если проблемы возникают на уровне физического хоста. Виртуализация может перезапустить окружение Kubernetes за счёт высокой доступности (High Availability) на другом физическом сервере.
Операции: без виртуализации весь физический хост обычно принадлежит одному Kubernetes-кластеру. Это означает, что среда привязана к одной версии Kubernetes, что снижает скорость развития и делает апгрейды и операции сложными.
Именно поэтому каждый крупный управляемый Kubernetes-сервис работает на виртуальных машинах: виртуализация обеспечивает изоляцию, надёжность и операционную гибкость, необходимые в корпоративном масштабе.
Broadcom предоставляет лучшую платформу для размещения рабочих нагрузок
Инженерные команды Broadcom продолжают активно участвовать в upstream Kubernetes и вносят вклад в такие проекты, как Harbor, Cluster API и etcd.
С выпуском VCF 9 подразделение VCF компании Broadcom принесло в отрасль унифицированные операции, общую инфраструктуру и единые инструменты, независимые от форм-факторов рабочих нагрузок. Клиенты могут запускать ВМ и контейнеры/Kubernetes-нагрузки на одном и том же оборудовании и управлять ими одними и теми же инструментами, на которых миллионы специалистов построили свои навыки и карьеры. Предприятия и организации могут снизить капитальные и операционные расходы, стандартизировать операционную модель и модернизировать приложения и инфраструктуру, чтобы бизнес мог двигаться быстрее, защищать данные и повышать надёжность своих ключевых систем.
В этой части статьи мы продолжаем рассказывать об итогах 2025 года в плане серверной и настольной виртуализации на базе российских решений. Первую часть статьи можно прочитать тут.
Возможности VDI (виртуализации рабочих мест)
Импортозамещение коснулось не только серверной виртуализации, но и инфраструктуры виртуальных рабочих столов (VDI). После ухода VMware Horizon (сейчас это решение Omnissa) и Citrix XenDesktop российские компании начали внедрять отечественные VDI-решения для обеспечения удалённой работы сотрудников и центрального управления рабочими станциями. К 2025 году сформировался пул новых продуктов, позволяющих развернуть полнофункциональную VDI-платформу на базе отечественных технологий.
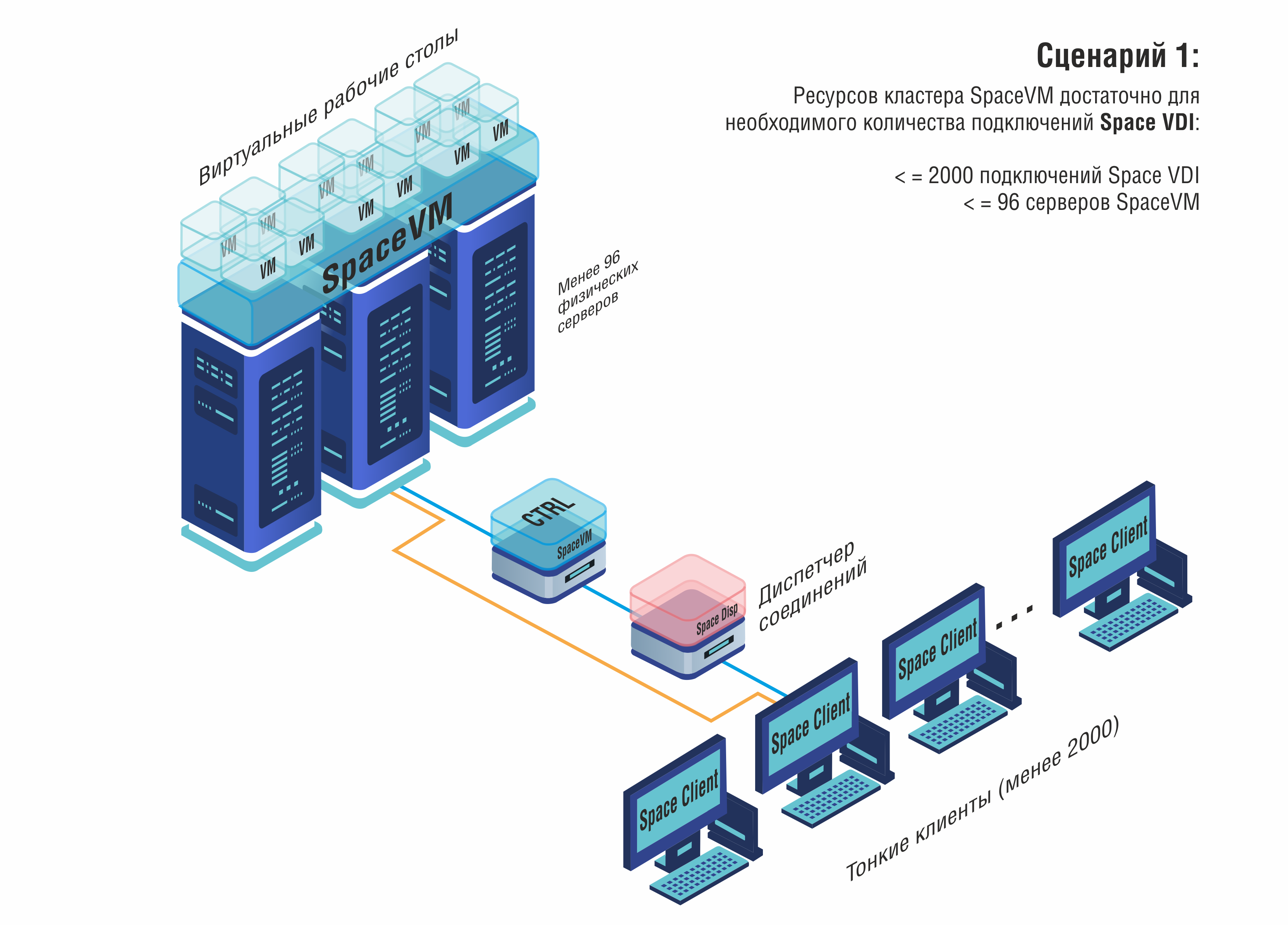
Лидерами рынка VDI стали решения, созданные в тесной связке с платформами серверной виртуализации. Так, компания «ДАКОМ М» (бренд Space) помимо гипервизора SpaceVM предложила продукт Space VDI – систему управления виртуальными рабочими столами, интегрированную в их экосистему. Space VDI заняла 1-е место в рейтинге российских VDI-решений 2025 г., набрав 228 баллов по совокупности критериев.
Её сильные стороны – полностью собственная разработка брокера и агентов (не опирающаяся на чужие open-source) и наличие всех компонентов, аналогичных VMware Horizon: Space Dispatcher (диспетчер VDI, альтернатива Horizon Connection Server), Space Agent VDI (клиентский агент на виртуальной машине, аналог VMware Horizon Agent), Space Client для подключения с пользовательских устройств, и собственный протокол удалённых рабочих столов GLINT. Протокол GLINT разработан как замена зарубежных (RDP/PCoIP), оптимизирован для работы в российских сетях и обеспечивает сжатие/шифрование трафика. В частности, заявляется поддержка мультимедиа-ускорения и USB-перенаправления через модуль Mediapipe, который служит аналогом Citrix HDX. В результате Space VDI предоставляет высокую производительность графического интерфейса и мультимедиа, сравнимую с мировыми аналогами, при этом полностью вписывается в отечественный контур безопасности.
Вторым крупным игроком стала компания HOSTVM с продуктом HostVM VDI. Этот продукт изначально основыван на открытой платформе UDS (VirtualCable) и веб-интерфейсе на Angular, но адаптирован российским разработчиком. HostVM VDI поддерживает широкий набор протоколов – SPICE, RDP, VNC, NX, PCoIP, X2Go, HTML5 – фактически покрывая все популярные способы удалённого доступа. Такая всеядность упрощает миграцию с иностранных систем: например, если ранее использовался протокол PCoIP (как в VMware Horizon), HostVM VDI тоже его поддерживает. Решение заняло 2-е место в отраслевом рейтинге с 218 баллами, немного уступив Space VDI по глубине интеграции функций.
Своеобразный подход продемонстрировал РЕД СОФТ. Их продукт «РЕД Виртуализация» является, в первую очередь, серверной платформой (форком oVirt на KVM) для развертывания ВМ. Однако благодаря тесной интеграции с РЕД ОС и другим ПО компании, Red Виртуализация может использоваться и для VDI-сценариев. Она заняла 3-е место в рейтинге VDI-платформ. По сути, РЕД предлагает создать инфраструктуру на базе своего гипервизора и доставлять пользователям рабочие столы через стандартные протоколы (для Windows-ВМ – RDP, для Linux – SPICE или VNC). В частности, поддерживаются протоколы VNC, SPICE и RDP, что покрывает базовые потребности. Кроме того, заявлена возможность миграции виртуальных машин в РЕД Виртуализацию прямо из сред VMware vSphere и Microsoft Hyper-V, что упрощает переход на решение.
Далее, существуют специализированные отечественные VDI-продукты: ROSA VDI, Veil VDI, Termidesk и др.
ROSA VDI (разработка НТЦ ИТ РОСА) базируется на том же oVirt и ориентирована на интеграцию с российскими ОС РОСА.
Veil VDI – решение компаний «НИИ Масштаб»/Uveon – представляет собственную разработку брокера виртуальных рабочих столов; оно также попало в топ-5 рейтинга.
Termidesk – ещё одна проприетарная система, замыкающая первую шестёрку лидеров. Каждая из них предлагает конкурентоспособные функции, хотя по некоторым пунктам уступает лидерам. Например, Veil VDI и Termidesk пока набрали меньше баллов (182 и 174 соответственно) и, вероятно, имеют более узкую специализацию или меньшую базу внедрений.
Общей чертой российских VDI-платформ является ориентация на безопасность и импортозамещение. Все они зарегистрированы как отечественное ПО и могут применяться вместо VMware Horizon, Citrix или Microsoft RDS. С точки зрения пользовательского опыта, основные функции реализованы: пользователи могут подключаться к своим виртуальным рабочим столам с любых устройств (ПК, тонкие клиенты, планшеты) через удобные клиенты или даже браузер. Администраторы получают централизованную консоль для создания образов ВМ, массового обновления ПО на виртуальных рабочих столах и мониторинга активности пользователей. Многие решения интегрируются с инфраструктурой виртуализации серверов – например, Space VDI напрямую работает поверх гипервизора SpaceVM, ROSA VDI – поверх ROSA Virtualization, что упрощает установку.
Отдельно стоит отметить поддержку мультимедийных протоколов и оптимизацию трафика. Поскольку качество работы VDI сильно зависит от протокола передачи картинки, разработчики добавляют собственные улучшения. Мы уже упомянули GLINT (Space) и широкий набор протоколов в HostVM. Также используется протокол Loudplay – это отечественная разработка в области облачного гейминга, адаптированная под VDI.
Некоторые платформы (например, Space VDI, ROSA VDI, Termidesk) заявляют поддержку Loudplay наряду со SPICE/RDP, чтобы обеспечить плавную передачу видео и 3D-графики даже в сетях с высокой задержкой. Терминальные протоколы оптимизированы под российские условия: так, Termidesk применяет собственный кодек TERA для сжатия видео и звука. В результате пользователи могут комфортно работать с графическими приложениями, CAD-системами и видео в своих виртуальных десктопах.
С точки зрения масштабируемости VDI, российские решения способны обслуживать от десятков до нескольких тысяч одновременных пользователей. Лабораторные испытания показывают, что Space VDI и HostVM VDI могут управлять тысячами виртуальных рабочих столов в распределенной инфраструктуре (с добавлением необходимых серверных мощностей). Важным моментом остаётся интеграция со средствами обеспечения безопасности: многие платформы поддерживают подключение СЗИ для контроля за пользователями (DLP-системы, антивирусы на виртуальных рабочих местах) и могут работать в замкнутых контурах без доступа в интернет.
Таким образом, к концу 2025 года отечественные VDI-платформы покрывают основные потребности удалённой работы. Они позволяют централизованно развертывать и обновлять рабочие места, сохранять данные в защищённом контуре датацентра и предоставлять сотрудникам доступ к нужным приложениям из любой точки. При этом особый акцент сделан на совместимость с российским стеком (ОС, ПО, требования регуляторов) и на возможность миграции с западных систем с минимальными затратами (поддержка разных протоколов, перенос ВМ из VMware/Hyper-V). Конечно, каждой организации предстоит выбрать оптимальный продукт под свои задачи – лидеры рынка (Space VDI, HostVM, Red/ROSA) уже имеют успешные внедрения, тогда как нишевые решения могут подойти под специальные сценарии.
Кластеризация, отказоустойчивость и управление ресурсами
Функциональность, связанная с обеспечением высокой доступности (HA) и отказоустойчивости, а также удобством управления ресурсами, является критичной при сравнении платформ виртуализации. Рассмотрим, как обстоят дела с этими возможностями у российских продуктов по сравнению с VMware vSphere.
Кластеризация и высокая доступность (HA)
Почти все отечественные системы поддерживают объединение хостов в кластеры и автоматический перезапуск ВМ на доступных узлах в случае сбоя одного из серверов – аналог функции VMware HA. Например, SpaceVM имеет встроенную поддержку High Availability для кластеров: при падении хоста его виртуальные машины автоматически запускаются на других узлах кластера.
Basis Dynamix, VMmanager, Red Virtualization – все они также включают механизмы мониторинга узлов и перезапуска ВМ при отказе, что отражено в их спецификациях (наличие HA подтверждалось анкетами рейтингов). По сути, обеспечение базовой отказоустойчивости сейчас является стандартной функцией для любых платформ виртуализации. Важно отметить, что для корректной работы HA требуется резерв мощности в кластере (чтобы были свободные ресурсы для поднятия упавших нагрузок), поэтому администраторы должны планировать кластеры с некоторым запасом хостов, аналогично VMware.
Fault Tolerance (FT)
Более продвинутый режим отказоустойчивости – Fault Tolerance, при котором одна ВМ дублируется на другом хосте в режиме реального времени (две копии работают синхронно, и при сбое одной – вторая продолжает работать без прерывания сервиса). В VMware FT реализован для критичных нагрузок, но накладывает ограничения (например, количество vCPU). В российских решениях прямая аналогия FT практически не встречается. Тем не менее, некоторые разработчики заявляют поддержку подобных механизмов. В частности, Basis Dynamix Enterprise в материалах указывал наличие функции Fault Tolerance. Однако широкого распространения FT не получила – эта технология сложна в реализации, а также требовательна к каналам связи. Обычно достаточен более простой подход (HA с быстрым перезапуском, кластерные приложения на уровне ОС и т.п.). В критических сценариях (банковские системы реального времени и др.) могут быть построены решения с FT на базе метрокластеров, но это скорее штучные проекты.
Снапшоты и резервное копирование
Снимки состояния ВМ (snapshots) – необходимая функция для безопасных изменений и откатов. Все современные платформы (zVirt, SpaceVM, Red и прочие) поддерживают создание мгновенных снапшотов ВМ в рабочем состоянии. Как правило, доступны возможности делать цепочки снимков, однако требования к хранению диктуют, что постоянно держать много снапшотов нежелательно (как и в VMware, где они влияют на производительность). Для резервного копирования обычно предлагается интеграция с внешними системами бэкапа либо встроенные средства экспорта ВМ.
Например, SpaceVM имеет встроенное резервное копирование ВМ с возможностью сохранения бэкапов на удалённое хранилище. VMmanager от ISPsystem также предоставляет модуль бэкапа. Тем не менее, организации часто используют сторонние системы резервирования – здесь важно, что у российских гипервизоров обычно открыт API для интеграции. Почти все продукты предоставляют REST API или SDK, позволяющий автоматизировать задачи бэкапа, мониторинга и пр. Отдельные вендоры (например, Basis) декларируют принцип API-first, что упрощает связку с оркестраторами резервного копирования и мониторинга.
Управление ресурсами и балансировка
Мы уже упоминали наличие аналогов DRS в некоторых платформах (автоматическое перераспределение ВМ). Кроме этого, важно, как реализовано ручное управление ресурсами: пулы CPU/памяти, приоритеты, квоты. В VMware vSphere есть ресурсные пулы и shares-приоритеты. В российских системах подобные механизмы тоже появляются. zVirt, например, позволяет объединять хосты в логические группы и задавать политику размещения ВМ, что помогает распределять нагрузку. Red Virtualization (oVirt) исторически поддерживает задание весов и ограничений на ЦП и ОЗУ для групп виртуальных машин. В Basis Dynamix управление ресурсами интегрировано с IaC-инструментами – можно через Terraform описывать необходимые ресурсы, а платформа сама их выделит.
Такое тесное сочетание с DevOps-подходами – одно из преимуществ новых продуктов: Basis и SpaceVM интегрируются с Ansible, Terraform для автоматического развертывания инфраструктуры как кода. Это позволяет компаниям гибко управлять ИТ-ресурсами и быстро масштабировать кластеры или развертывать новые ВМ по шаблонам.
Управление кластерами
Центральная консоль управления кластером – обязательный компонент. Аналог VMware vCenter в отечественных решениях присутствует везде, хотя может называться по-разному. Например, у Space – SpaceVM Controller (он же выполняет роль менеджера кластера, аналог vCenter). У zVirt – собственная веб-консоль, у Red Virtualization – знакомый интерфейс oVirt Engine, у VMmanager – веб-панель от ISPsystem. То есть любой выбранный продукт предоставляет единый интерфейс для управления всеми узлами, ВМ и ресурсами. Многие консоли русифицированы и достаточно дружелюбны. Однако по отзывам специалистов, удобство администрирования ещё требует улучшений: отмечается, что ряд операций в отечественных платформах более трудоёмкие или требуют «танцев с бубном» по сравнению с отлаженным UI VMware. Например, на Хабре приводился пример, что создание простой ВМ в некоторых системах превращается в квест с редактированием конфигурационных файлов и чтением документации, тогда как в VMware это несколько кликов мастера создания ВМ. Это как раз то направление, где нашим решениям ещё есть куда расти – UX и простота администрирования.
В плане кластеризации и отказоустойчивости можно заключить, что функционально российские платформы предоставляют почти весь минимально необходимый набор возможностей. Кластеры, миграция ВМ, HA, снапшоты, бэкап, распределенная сеть, интеграция со сториджами – всё это реализовано (см. сводную таблицу ниже). Тем не менее, зрелость реализации зачастую ниже: возможны нюансы при очень крупных масштабах, не все функции могут быть такими же «отполированными» как у VMware, а администрирование требует большей квалификации.
Платформа
Разработчик
Технологическая основа
Особенности архитектуры
Ключевые сильные стороны
Известные ограничения
Basis Dynamix
БАЗИС
Собственная разработка (KVM-совместима)
Классическая и гибридная архитектура (есть Standard и Enterprise варианты)
Высокая производительность, интеграция с Ansible/Terraform, единая экосистема (репозиторий, поддержка); востребован в госсекторе.
Мало публичной информации о тонкостях; относительно новый продукт, требует настройки под задачу.
SpaceVM
ДАКОМ M (Space)
Проприетарная (собственный стек гипервизора)
Классическая архитектура, интеграция с внешними СХД + проприетарные HCI-компоненты (FreeGRID, SDN Flow)
Максимально функциональная платформа: GPU-виртуализация (FreeGRID), своя SDN (аналог NSX), полный VDI-комплекс (Space VDI) и собственные протоколы; высокое быстродействие.
Более сложное администрирование (богатство функций = сложность настроек).
zVirt
Orion soft
Форк oVirt (KVM) + собственный бэкенд
Классическая модель, SDN-сеть внутри (distributed vSwitch)
Богатый набор функций: микросегментация сети SDN, Storage Live Migration, авто-балансировка ресурсов (DRS-аналог), совместим с открытой экосистемой oVirt; крупнейшая инсталляционная база (21k+ хостов ожидается).
Проблемы масштабируемости на очень больших кластерах (>50 узлов); интерфейс менее удобен, чем VMware (выше порог входа).
Red Виртуализация
РЕД СОФТ
Форк oVirt (KVM)
Классическая схема, тесная интеграция с РЕД OS и ПО РЕД СОФТ
Знакомая VMware-подобная архитектура; из коробки многие функции (SAN, HA и др.); сертификация ФСТЭК РЕД ОС дает базу для безопасности; успешные кейсы миграции (Росельхозбанк, др.).
Более ограниченная экосистема поддержки (сильно завязана на продукты РЕД); обновления зависят от развития форка oVirt (нужны ресурсы на самостоятельную разработку).
vStack HCP
vStack (Россия)
FreeBSD + bhyve (HCI-платформа)
Гиперконвергентная архитектура, собственный легковесный гипервизор
Минимальные накладные расходы (2–5% CPU), масштабируемость «без ограничений» (нет фикс. лимитов на узлы/ВМ), единый веб-интерфейс; независим от Linux.
Относительно новая/экзотичная технология (FreeBSD), сообщество меньше; возможно меньше совместимых сторонних инструментов (бэкап, драйверы).
Cyber Infrastructure
Киберпротект
OpenStack + собственные улучшения (HCI)
Гиперконвергенция (Ceph-хранилище), поддержка внешних СХД
Глубокая интеграция с резервным копированием (наследие Acronis), сертификация ФСТЭК AccentOS (OpenStack), масштабируемость для облаков; работает на отечественном оборудовании.
Менее подходит для нагрузок, требующих стабильности отдельной ВМ (особенности OpenStack); сложнее в установке и сопровождении без экспертизы OpenStack.
Другие (ROSA, Numa, HostVM)
НТЦ ИТ РОСА, Нума Техн., HostVM
KVM (oVirt), Xen (xcp-ng), KVM+UDS и др.
В основном классические, частично HCI
Закрывают узкие ниши или предлагают привычный функционал для своих аудиторий (например, Xen для любителей XenServer, ROSA для Linux-инфраструктур). Часто совместимы с специфическими отечественными ОС (ROSA, ALT).
Как правило, менее функционально богаты (ниже баллы рейтингов); меньшая команда разработки = более медленное развитие.
Поддержание доступности данных и приложений, которые эти данные создают или используют, может быть одной из самых важных задач администраторов центров обработки данных. Такие возможности, как высокая производительность или специализированные службы данных, мало что значат, если приложения и данные, которые они создают или используют, недоступны. Обеспечение доступности — это сложная тема, поскольку доступность приложений и доступность данных достигаются разными методами. Иногда требования к доступности реализуются с помощью механизмов на уровне инфраструктуры, а иногда — с использованием решений, ориентированных на приложения. Оптимальный вариант для вашей среды во многом зависит от требований и возможностей инфраструктуры.
Хотя VMware Cloud Foundation (VCF) может обеспечивать высокий уровень доступности данных и приложений простым способом, в этой статье рассматриваются различия между обеспечением высокой доступности приложений и данных с использованием технологий на уровне приложений и встроенных механизмов на уровне инфраструктуры в VCF. Мы также рассмотрим, как VMware Data Services Manager (DSM) может помочь упростить принятие подобных решений.
Учёт отказов
Защита приложений и данных требует понимания того, как выглядят типичные сбои, и что система может сделать для их компенсации. Например, сбои в физической инфраструктуре могут затрагивать:
Централизованные решения для хранения, такие как дисковые массивы
Отдельные устройства хранения в распределённых системах
Такие сбои могут затронуть данные, приложения, или и то, и другое. Сбои могут проявляться по-разному — некоторые явно, другие лишь по отсутствию отклика. Часть из них временные, другие — постоянные. Решения должны быть достаточно интеллектуальными, чтобы автоматически справляться с такими ситуациями отказа и восстановления.
Доступность и восстановление приложений и данных
Доступность приложений и их наборов данных кажется интуитивно понятной, но требует краткого пояснения.
Доступность приложения
Это состояние приложения, например базы данных или веб-приложения. Независимо от того, установлено ли оно в виртуальной машине или запущено в контейнере, приложение заранее настроено на работу с данными определённым образом. Некоторые приложения могут работать в нескольких экземплярах для повышения доступности при сбоях и использовать собственные механизмы синхронной репликации, чтобы данные сохранялись в нескольких местах. Технологии, такие как vSphere HA, могут повысить доступность приложения и его данных, перезапуская виртуальную машину на другом хосте кластера vSphere в случае сбоя.
Доступность данных
Это способность данных быть доступными для приложения или пользователей в любое время, даже при сбое. Высокодоступные данные хранятся с использованием устойчивых механизмов, обеспечивающих хранение в нескольких местах — в зависимости от возможных границ сбоя: устройства, хоста, массива хранения или целого сайта.
Надёжность данных
Хранить данные в нескольких местах недостаточно — они должны записываться синхронно и последовательно во все копии, чтобы при сбое данные из одного места совпадали с данными из другого. Корпоративные системы хранения данных реализуют принципы ACID (атомарность, согласованность, изолированность, долговечность) и протоколы, обеспечивающие надёжность данных.
Описанные выше концепции вводят два термина, которые помогают количественно определить возможности восстановления в случае сбоя:
RPO (Recovery Point Objective) — целевая точка восстановления. Показывает, с каким интервалом данные защищаются устойчивым образом. RPO=0 означает, что система всегда выполняет запись в синхронном, согласованном состоянии. Как будет отмечено далее, не все решения способны обеспечивать настоящий RPO=0.
RTO (Recovery Time Objective) — целевое время восстановления. Показывает минимальное время, необходимое для восстановления систем и/или данных до рабочего состояния. Например, RTO=10m означает, что восстановление займёт не менее 10 минут. RTO может относиться к восстановлению доступности данных или комбинации данных и приложения.
Эволюция решений для высокой доступности
Подходы к обеспечению доступности данных и приложений эволюционировали с развитием технологий и ростом требований. Некоторые приложения, такие как Microsoft SQL Server, MySQL, PostgreSQL и другие, включают собственные механизмы репликации, обеспечивающие избыточность данных и состояния приложения. Виртуализация, совместно с общим хранилищем, предоставляет простые способы обеспечения высокой доступности приложений и хранимых ими данных.
В зависимости от ваших требований может подойти один из подходов или их комбинация. Рассмотрим, как каждый из них обеспечивает высокий уровень доступности.
Высокая доступность на уровне приложений (Application-Level HA)
Этот подход основан на запуске нескольких экземпляров приложения в разных местах. Синхронное и устойчивое хранилище, а также механизмы отказоустойчивости обеспечиваются самим приложением для гарантии высокой доступности приложения и его данных.
Высокая доступность на уровне инфраструктуры (Infrastructure-Level HA)
Этот подход использует vSphere HA для перезапуска одного экземпляра приложения на другом хосте кластера. Синхронное и устойчивое хранение данных обеспечивает VMware vSAN (в контексте данного сравнения). Такая комбинация гарантирует высокую доступность приложения и его данных.
Оба подхода достигают схожих целей, но имеют определённые компромиссы. Рассмотрим два простых примера, чтобы лучше понять различия.
В приведённых примерах предполагается, что данные должны сохраняться в нескольких местах (например, на уровне сайта или зоны), чтобы обеспечить доступность при сбое площадки. Также предполагается, что приложение может работать в тех же местах. Оба варианта обеспечивают автоматический отказоустойчивый переход и RPO=0, поскольку данные записываются синхронно в несколько мест.
Высокая доступность на уровне приложений для приложений и данных
Высокая доступность на уровне приложений, как в случае MS SQL Always On Availability Groups (AG), использует два или более работающих экземпляра базы данных и дополнительное местоположение для определения кворума при различных сценариях отказа.
Этот подход полностью опирается на технологии, встроенные в само приложение, чтобы синхронно реплицировать данные в другое место и обеспечить механизм отказоустойчивого переключения состояния приложения.
Высокая доступность на уровне инфраструктуры для приложений и данных
Высокая доступность на уровне инфраструктуры использует приложение базы данных, работающее на одной виртуальной машине. vSphere HA обеспечивает автоматическое восстановление приложения, обращающегося к данным, в то время как vSAN гарантирует надёжность и доступность данных при различных типах сбоев инфраструктуры.
vSAN может выдерживать отказы отдельных устройств хранения, сетевых карт (NIC), сетевых коммутаторов, хостов и даже целых географических площадок или зон, которые определяются как «домен отказа» (fault domain).
В приведённом ниже примере кластер vSAN растянут между двумя площадками, чтобы обеспечить устойчивое хранение данных на обеих. Растянутые кластеры vSAN (vSAN Stretched Clusters) также используют третью площадку, на которой размещается небольшой виртуальный модуль — witness host appliance (хост-свидетель), помогающий определить кворум при различных возможных сценариях отказа.
Одним из самых убедительных преимуществ высокой доступности на уровне инфраструктуры является то, что в VCF она является встроенной частью платформы. vSAN интегрирован прямо в гипервизор и обеспечивает отказоустойчивость данных в соответствии с вашими требованиями, всего лишь посредством настройки простой политики хранения (storage policy). Экземпляры приложений становятся высокодоступными благодаря проверенной технологии vSphere HA, которая позволяет перезапускать виртуальные машины на любом хосте в пределах кластера vSphere. Такой подход также отлично работает, когда приложения баз данных развертываются и управляются в вашей среде VCF с помощью DSM.
Разные подходы к обеспечению согласованности данных
Хотя оба подхода могут обеспечивать цель восстановления точки (RPO), равную нулю (RPO=0), за счёт синхронной репликации, способы достижения этого различаются. Оба используют специальные протоколы, помогающие обеспечить согласованность данных, записываемых в нескольких местах — что на практике значительно сложнее, чем кажется.
В случае MS SQL Server Always On Availability Groups согласованность достигается на уровне приложения, тогда как vSAN обеспечивает синхронную запись данных по своей сути — как часть распределённой архитектуры, изначально разработанной для обеспечения отказоустойчивости.
При репликации данных на уровне приложения такой высокий уровень доступности ограничен только этим конкретным приложением и его данными. Однако возможности на уровне приложений реализованы не одинаково. Например, MS SQL Server Always On AG могут обеспечивать RPO=0 при множестве сценариев отказа, тогда как MySQL InnoDB Cluster использует подход, при котором RPO=0 возможно только при отказе одного узла. Хотя данные при этом остаются согласованными, в некоторых сценариях отказа — например, при полном сбое кластера или незапланированной перезагрузке — могут быть потеряны последние зафиксированные транзакции. Это означает, что при определённых обстоятельствах обеспечить истинный RPO=0 невозможно.
В случае vSAN в составе VCF, высокая доступность является универсальной характеристикой, которая применяется ко всем рабочим нагрузкам, записывающим данные в хранилище vSAN datastore.
Различия во времени восстановления (RTO)
Одной из основных причин различий между возможностями RTO при доступности на уровне приложения и на уровне инфраструктуры является то, как приложение возвращается в рабочее состояние после сбоя.
Например, некоторые приложения, такие как SQL Server AG, используют лицензированные «резервные» виртуальные машины (standby VMs) в вашей инфраструктуре, чтобы обеспечить использование другого состояния приложения при отказе. Это позволяет достичь низкого RTO, но приводит к увеличению затрат из-за необходимости дополнительных лицензий и потребляемых ресурсов. Высокая доступность на уровне приложения — это специализированное решение, требующее экспертизы в конкретном приложении для достижения нужного результата. Однако DSM может значительно снизить сложность таких сценариев, поскольку автоматизирует эти процессы и снимает значительную часть административной нагрузки.
Высокая доступность на уровне инфраструктуры работает иначе. Используя механизмы виртуализации, такие как vSphere High Availability (HA), она обеспечивает перезапуск приложения в другом месте при сбое виртуальной машины. Перезапуск ВМ и самого приложения, а также процесс восстановления журналов обычно занимают больше времени, чем подход с резервной ВМ, используемый при высокой доступности на уровне приложений.
Приведённые выше значения времени восстановления являются оценочными. Фактическое время восстановления может значительно различаться в зависимости от условий среды, размера и активности экземпляра MS SQL.
Что выбрать именно вам?
Наилучший выбор зависит от ваших требований, ограничений и того, насколько решение подходит вашей организации. Например:
Требования к доступности
Возможно, ваши требования предполагают, что приложение и его данные должны быть доступны за пределами определённой границы отказа — например, уровня сайта или зоны. Это поможет определить, нужна ли вообще доступность на уровне сайта или зоны.
Требования к RTO
Если требуемое время восстановления (RTO) допускает 2–5 минут, то высокая доступность на уровне инфраструктуры — отличный вариант, поскольку она встроена в платформу и работает для всех ваших нагрузок. Если же есть несколько отдельных приложений, для которых требуется меньшее RTO, и вас не смущают дополнительные затраты и сложность, связанные с этим решением, то подход на уровне приложения может быть оправдан.
Технические ограничения
В вашей организации могут быть инициативы по упрощению инструментов и рабочих процессов, что может ограничивать возможность или желание использовать дополнительные технологии, такие как высокая доступность на уровне приложений. Обычно предпочтение отдаётся универсальным инструментам, применимым ко всем системам, а не узкоспециализированным решениям. Другие технические факторы, например задержки (latency) между сайтами или зонами, также могут сделать тот или иной подход непрактичным.
Финансовые ограничения
Возможно, на вас оказывают давление с целью сократить постоянные расходы на программное обеспечение — например, на дополнительные лицензии или более дорогие уровни лицензирования, необходимые для обеспечения высокой доступности на уровне приложений. В этом случае более выгодным решением могут оказаться уже имеющиеся технологии.
Можно также использовать комбинацию обоих подходов.
Например, на первом рисунке в начале статьи показано, как высокая доступность на уровне приложений реализуется между сайтами или зонами с помощью MS SQL Always On Availability Groups, а высокая доступность на уровне инфраструктуры обеспечивается vSAN и vSphere HA внутри каждого сайта или зоны.
Этот вариант также может быть отличным примером использования VMware Data Services Manager (DSM). Вместо запуска и управления отдельными виртуальными машинами можно использовать базы данных, развёрнутые DSM, для обеспечения доступности приложений между сайтами или зонами. Такой подход обеспечивает низкое RTO, устраняет административную сложность, связанную с репликацией на уровне приложений, и при этом позволяет vSAN обеспечивать доступность данных внутри сайтов или зон.
В условиях ухода западных вендоров с российского рынка и активного импортозамещения, спрос на отечественные платформы виртуализации значительно вырос. Одним из наиболее ярких и амбициозных проектов в этой области является «Иридиум», решение компании РТ-Иридиум, предназначенное для построения отказоустойчивой и масштабируемой виртуальной инфраструктуры. В июле 2025 года был представлен релиз «Иридиум» 2.0, вобравший в себя широкий набор корпоративных функций.
Архитектура и технологическая база
Платформа «Иридиум» построена на базе гипервизора KVM/QEMU — проверенного временем решения с открытым исходным кодом, которое активно используется и в других коммерческих продуктах (в том числе в ROSA Virtualization и Proxmox). Использование KVM обеспечивает высокую производительность, гибкость, поддержку современных функций виртуализации, а также совместимость с отечественным оборудованием.
Компоненты архитектуры «Иридиум»:
Гипервизор: KVM (работает на Linux, взаимодействует с аппаратной виртуализацией через Intel VT-x/AMD-V).
Управляющая панель: web-интерфейс с ролью диспетчера и оркестратора (аналог vCenter).
VSAN-подобное хранилище: поддержка отказоустойчивого кластера хранения.
Система управления пользователями и политиками безопасности (в том числе LDAP, SSO).
Интеграция с Docker-контейнерами — что делает платформу применимой не только для ВМ, но и для микросервисных архитектур.
Кластеры высокой доступности — объединение до 64 физических узлов с горячей миграцией и автоматическим восстановлением ВМ.
Новые возможности в версии 2.0
Релиз «Иридиум» 2.0 вывел продукт на уровень зрелого корпоративного решения. В числе ключевых новшеств:
HA-кластеры (High Availability) — автоматическое восстановление ВМ при сбое узла.
Горячая и холодная миграция виртуальных машин между узлами.
Встроенное резервное копирование и восстановление.
Поддержка VDI-сценариев (виртуальных рабочих столов).
Контроль доступа и кросс-доменная авторизация.
Новая панель мониторинга с метриками и журналами аудита.
Совместимость с российскими серверами (например, RDW Computers), включая проверку отказоустойчивости.
Сравнение с конкурентами
Характеристика
Иридиум 2.0
ROSA Virtualization
VMware vSphere
Основа гипервизора
KVM/QEMU
KVM/QEMU
Собственный гипервизор ESXi
Интерфейс управления
Web UI, REST API
Web UI (на базе Cockpit)
vCenter
Горячая миграция ВМ
Да
Да
Да
Кластеры высокой доступности
Да
Ограниченно (в Enterprise)
Да (через vSphere HA)
Поддержка VDI
Да
Нет (только через сторонние решения)
Да (через Omnissa)
Репликация и бэкапы
Встроенные
Через сторонние решения
Через Veeam, vSphere Replication
Сертификация ФСТЭК
В процессе получения
Есть (у отдельных сборок)
Нет (нерелевантно для РФ после ухода)
Docker/контейнеры
Да (встроено)
Частично (в экспериментальных сборках)
Через Tanzu (Kubernetes)
Импортозамещение/локализация
Отечественная сборка на базе Open Source
Отечественная сборка на базе Open Source
Нет (не поддерживается в РФ)
Заключение
С выходом версии 2.0 платформа «Иридиум» совершила качественный скачок, превратившись в конкурентоспособную альтернативу западным решениям уровня VMware. Поддержка кластеров высокой доступности, встроенное резервное копирование, интерфейс управления и интеграция с VDI делают продукт особенно привлекательным для корпоративных клиентов, органов власти и критически важных объектов инфраструктуры.
Благодаря открытому гипервизору KVM, российской разработке, масштабируемости и активной интеграции с отечественным «железом», «Иридиум» становится не просто ответом на уход VMware, но полноценным участником новой экосистемы российских ИТ-решений.
Одной из ключевых инженерных инициатив в VMware Cloud Foundation 9 (VCF 9) стало улучшение пользовательского опыта при развертывании. VMware не только упростила процесс развертывания нового экземпляра VCF, но и расширила поддержку различных типов топологий и сценариев развертывания. В результате пользователи vSphere получают более простой, быстрый и воспроизводимый процесс перехода на VCF.
VMware Cloud Foundation 9 предлагает несколько вариантов развертывания для модернизации инфраструктуры:
Развертывание нового экземпляра VCF
Расширение существующего пула VCF (VCF Fleet)
Конвертация существующего развертывания vCenter в VCF
Импорт существующего развертывания vCenter в VCF
Начнём с того, как происходит развертывание и масштабирование VCF 9.
VMware Cloud Foundation 9 — это крупный релиз, включающий ряд важных новых возможностей и более интегрированный опыт для администраторов частных облаков. Виртуальный модуль установщика VMware Cloud Foundation (VCF Installer) — это новый компонент в VCF 9, предоставляющий более гибкие сценарии развертывания, подходящие для расширенного набора задач.
VCF Installer можно использовать для:
Развертывания нового экземпляра VCF как части нового пула (Fleet)
Если у заказчика уже есть несколько сред, он может развернуть дополнительные экземпляры VCF в существующем пуле.
Каждый экземпляр VCF развёртывается с использованием vSphere и сервера vCenter, NSX, VCF Operations и VCF Automation. Настройка VCF-среды с использованием vSAN обеспечивает полный стек SDDC (программно-определяемого датацентра).
VCF Installer также содержит встроенные рабочие процессы для конвертации (повторного использования) существующего развертывания vCenter в управляющий кластер VCF. В этом сценарии под существующей средой vCenter понимается развертывание вне VCF. При выполнении конвертации VCF Installer развертывается в том же кластере, где находится виртуальный модуль сервера vCenter. VMware поддерживает как кластеры vCenter, настроенные с vSAN, так и кластеры, использующие внешнее хранилище.
После конвертации среда становится полноценным экземпляром VCF, которым можно управлять, масштабировать и обслуживать на протяжении всего жизненного цикла как обычный VCF.
И это ещё не всё, что умеет VCF Installer. Рабочий процесс установщика также предоставляет возможность конвертировать существующий экземпляр VCF Operations и/или VCF Automation. Виртуальный модуль VCF Installer обеспечивает более простой, быстрый и воспроизводимый процесс перехода к VMware Cloud Foundation для клиентов.
Подробнее о виртуальном модуле VCF Installer
Виртуальный модуль VCF Installer заменяет Cloud Builder, использовавшийся в предыдущих версиях VCF. Он предоставляет гибкий набор опций, ещё больше упрощающих развертывание полноценной частной облачной среды.
VCF Installer содержит интерфейс с пошаговым управлением (UI-driven workflow) и больше не требует использования файла Deployment Parameters Workbook (таблица Excel). Также в него встроены функции конвертации и импорта существующих инстанций vCenter, VCF Operations и VCF Automation — без необходимости использовать скрипты VCF Import.
В предыдущих версиях Cloud Foundation требовалось устанавливать Aria Operations и Aria Automation отдельно и управлять ими на этапе Day 2 (после начального развертывания). Начиная с VCF 9, VCF Installer используется для развертывания всего стека VCF, включая гипервизор vSphere, хранилище, сеть, управление и самообслуживание, а VCF Operations отвечает за полное управление жизненным циклом этого стека.
Как работает VCF Installer?
В этом новом и очень легковесном виртуальном модуле VCF Installer встроен набор усовершенствованных сценариев развертывания и множество новых параметров конфигурации.
При подключении к порталу поддержки Broadcom пользователь загружает программные бинарные файлы, подключаясь к онлайн-репозиторию. В отличие от Cloud Builder, модуль VCF Installer не содержит бинарных файлов ПО.
Пользователи также могут настроить собственный автономный (offline) репозиторий, который можно использовать для нескольких экземпляров VCF. В этом случае бинарные файлы необходимо загрузить только один раз, что удобно при управлении несколькими экземплярами VCF.
После загрузки бинарных файлов модуль можно использовать для развертывания VMware Cloud Foundation (VCF) или VMware vSphere Foundation (VVF). Развертывание можно выполнить с помощью встроенного мастера установки или путем загрузки JSON-спецификации, которую можно повторно использовать, просматривать и валидировать через интерфейс. JSON-спецификацию также можно редактировать прямо в мастере установки.
Экземпляр VCF может быть развернут как часть нового пула (VCF Fleet) или добавлен к существующему пулу. VCF Fleet может включать в себя несколько развертываний VCF, использующих общие экземпляры VCF Operations и VCF Automation.
VCF Installer используется для начальной настройки управляющего кластера, который можно развернуть двумя способами:
Развертывание новых компонентов, включая виртуальные машины для vCenter Server, NSX, VCF Operations и VCF Automation.
Использование уже существующих компонентов, например, существующих экземпляров vCenter Server, VCF Operations и VCF Automation.
При выборе конвертации (повторного использования) существующего vCenter Server, VCF Installer конвертирует существующий кластер vSphere или vSphere с vSAN в управляющий кластер VCF. В рамках этого процесса VCF Installer автоматически развёртывает NSX.
Если выбран повторный запуск уже существующего экземпляра VCF Operations, рекомендуется указать тот vCenter Server, на котором он размещена, в качестве управляющего vCenter для первого кластера VCF.
Виртуальные машины для новых экземпляров VCF Operations, VCF Automation и NSX можно развернуть в двух режимах:
Простой режим (Simple Model) — одноузловые виртуальные модули.
Режим высокой доступности (High Availability Model) — несколько модулей для отказоустойчивости.
После успешного развертывания VCF Installer предоставляет ссылку для запуска VCF Operations, который используется для управления.
Подробнее о двух моделях виртуальных модулей
Простой режим (Simple Model)
Минимум 7 виртуальных модулей:
1 для vCenter Server
1 для SDDC Manager
1 для NSX Manager
3 для VCF Operations: Operations Manager, Fleet Management, Operations Collector
1 для VCF Automation
Если выбрана опция Supervisor, разворачивается виртуальный модуль VKS. Дополнительно после установки можно развернуть:
Поддержку логов в VCF Operations
Безопасное подключение к NSX Edge кластеру
Базу данных VIDB для управления доступом и идентификацией
Модель высокой доступности (High Availability Model)
Рекомендуется для производственных сред. Развертывается минимум 13 виртуальных модулей:
3 NSX Manager
3 VCF Operations
3 VCF Automation
3 для логов и 1 для VKS
Наличие трёх экземпляров каждого компонента обеспечивает отказоустойчивость при сбоях оборудования, уменьшает влияние обновлений и упрощает управление жизненным циклом (патчи, апгрейды и т.д.). Также доступны дополнительные опции (не указаны выше), например, настройка балансировщиков нагрузки NSX для отдельных компонентов.
В любое время после установки клиент может масштабировать дополнительные компоненты. Дополнительно можно развернуть:
VCF Operations for Networks
HCX
Другие дополнительные сервисы VCF Advanced (Add-ons)
Как управлять средой VCF 9?
Начиная с VCF 9, управление и эксплуатация частного облака выполняются через консоль VCF Operations. VCF Operations предоставляет администраторам облака единый и функционально насыщенный интерфейс, охватывающий управление вычислениями, хранилищем, сетью, флотом экземпляров и жизненным циклом всей системы.
Но и это ещё не всё - VCF Operations для VCF 9 также включает встроенные рабочие процессы, которые поддерживают ещё два дополнительных сценария развертывания VCF. С помощью VCF Operations можно:
Создавать новые домены рабочих нагрузок (workload domains)
Импортировать существующие развертывания vCenter в существующий экземпляр VMware Cloud Foundation
Оба варианта позволяют масштабировать частное облако и обеспечивают централизованное управление и эксплуатацию.
Импорт существующих развертываний vCenter в экземпляр VMware Cloud Foundation
VCF Operations упрощает добавление существующей инфраструктуры vSphere, vSAN и NSX в уже развернутый экземпляр VCF. В интерфейсе доступны интерактивные пошаговые сценарии импорта существующей инфраструктуры vSphere в VCF в виде доменов рабочей нагрузки.
Возможность импорта уже существующей инфраструктуры позволяет клиентам ускорить переход к VCF, использовать уже сделанные инвестиции и одновременно снижать затраты. Более того, теперь не требуется вручную переносить рабочие нагрузки со старой инфраструктуры на VCF.
При импорте развертывания vCenter в VCF, все кластеры внутри этого сервера vCenter автоматически импортируются и настраиваются как часть домена рабочей нагрузки.
Можно импортировать:
Кластеры vSphere с или без vSAN
Кластеры с или без NSX
Любую комбинацию этих компонентов
Если NSX в кластере ещё не развернут, он будет установлен автоматически в процессе конвертации.
При импорте развертывания vCenter в экземпляр VCF все кластеры, находящиеся на этом сервере vCenter, импортируются и настраиваются как часть домена рабочей нагрузки. Этот сценарий в VCF Operations поддерживает широкий спектр конфигураций кластеров, которые часто встречаются в существующих средах vSphere.
Совместимость по хостам:
Хосты с одним физическим сетевым адаптером (pNIC)
Кластеры с включённым LACP
Одноузловые кластеры и отдельные хосты (standalone)
Совместимость по хранилищу:
Кластеры vSAN из 2 узлов
HCI Mesh
Кластеры хранения vSAN
Растянутые кластеры vSAN (stretched clusters)
Также можно импортировать кластеры, использующие внешние хранилища, например:
NFS
VMFS over Fibre Channel (FC)
iSCSI
Совместимость по сети:
Развертывания vCenter Server, как с NSX, так и без него, могут быть импортированы
Резюме
VMware Cloud Foundation 9 (VCF 9) предлагает несколько вариантов развертывания для модернизации вашей инфраструктуры:
Новые развертывания:
Для нового развертывания VCF 9 требуется минимум 4 хоста для управляющего кластера, который может быть развернут с использованием vSAN, NFS или VMFS по FC.
Начиная с VCF 9, управляющий кластер можно настраивать с помощью узлов vSAN Ready Nodes (рекомендуется).
Также поддерживается оборудование vSphere, сертифицированное для использования с топологиями хранения на NFS/VMFS over FC. Подробности — в руководстве по совместимости (Compatibility Guide).
Управляющий домен нового экземпляра VCF настраивается с использованием NSX. Каждый рабочий домен (Workload Domain) также конфигурируется с NSX и готов к использованию виртуальной сети NSX (SDN).
Расширение существующего VCF Fleet:
Развертывание нового экземпляра VCF как части уже существующего пула.
Каждый VCF Fleet управляется общими экземплярами VCF Operations и VCF Automation.
Конвертация существующего развертывания vCenter в VCF:
VMware поддерживает конвертацию (повторное использование) существующих кластеров vSphere в VCF.
Такие среды могут быть развернуты с vSphere или vSphere с vSAN.
Среды vCenter с уже установленным NSX пока не поддерживаются для конвертации в управляющий домен VCF. В процессе будет установлен новый экземпляр NSX.
Требуется минимум:
3 узла vSAN Ready.
Или 2 хоста vSphere, настроенные с NFS или VMFS over FC (cм. VCF configmax для дополнительной информации).
Импорт развертывания vCenter в VCF:
Требуется минимум:
3 узла vSAN Ready.
Или 2 хоста vSphere, настроенные с NFS или VMFS over FC (cм. VCF configmax для дополнительной информации).
Существующие среды vCenter с установленным NSX могут быть импортированы как домены рабочей нагрузки.
Режим оценки:
Новый экземпляр VCF развертывается в режиме оценки (evaluation mode).
В этом режиме VCF полностью функционален и позволяет развертывать дополнительные хосты, домены рабочей нагрузки и кластеры.
Экземпляр VCF 9 необходимо активировать лицензией в течение 90 дней с момента установки.
VCF Operations направляет пользователя в Broadcom Business Services Console для завершения процесса лицензирования.
Управление VCF через VCF Operations:
Начиная с VCF 9, VCF Operations используется для управления одним или несколькими экземплярами VCF.
SDDC Manager 9 устанавливается или обновляется как компонент любого экземпляра VCF 9.
SDDC Manager будет выведен из эксплуатации в одном из будущих релизов.
На прошедшей недавно конференции VeeamON 2025 было рассказано о скором выходе новой версии Veeam Backup & Replication 13, в которой будут представлены новые функции, направленные на повышение доступности (High Availability, HA), что позволяет компаниям поддерживать бесперебойную работу и защищать критически важные данные даже в случае непредвиденных ситуаций. Эта возможность уже давно запрашивалась пользователями, и вот, наконец, она будет реализована в производственной среде.
Помимо высокой доступности, Veeam Backup & Replication v13 предложит впечатляющие возможности, такие как развертывание сервера управления, хранилища, прокси и других компонентов напрямую из Veeam Software Appliance, мгновенное восстановление в Microsoft Azure, расширенное управление доступом на основе ролей (RBAC), а также множество других улучшений.
В Veeam Backup & Replication v13 возможности HA были расширены за счёт внедрения резервного управляющего сервера, готового к моментальному переключению при необходимости. В фоновом режиме репликация базы данных PostgreSQL обеспечивает постоянное дублирование всех конфигурационных данных, что гарантирует готовность системы к любым сбоям. При этом механизм репликации кэша, встроенный в базу данных, непрерывно передаёт данные на резервный сервер, обеспечивая его синхронность с основным узлом. Такая проактивная настройка устраняет время ожидания в случае аварии — резервная машина Veeam Backup & Replication полностью готова к работе и может быть активирована при необходимости.
На первом этапе функция HA будет доступна только для Veeam Backup & Replication на платформе Linux (дистрибутив основан на Rocky Linux). Процесс переключения выполняется вручную и по требованию — администраторы могут инициировать его в нужный момент, так как автоматические триггеры пока не предусмотрены. Архитектура реализована по схеме "активный-пассивный" с двумя узлами, с акцентом на надёжность.
Настройка сервера
После установки Veeam Backup & Replication v13 с помощью Veeam Software Appliance (в формате .ova или .iso), необходимо выполнить несколько базовых шагов конфигурации самого сервера. В этот процесс входят следующие ключевые этапы:
Настройка имени: присвойте виртуальному модулю понятное и информативное имя для его простой идентификации в инфраструктуре.
Сетевые настройки: установите сетевые параметры для надёжной связи с другими компонентами и резервным сервером.
Настройка NTP: укажите сервер синхронизации времени (Network Time Protocol), чтобы обеспечить точное совпадение времени на всех системах. Это критически важно, например, для проверки одноразовых паролей (OTP).
Пароль в соответствии с DISA STIG: создайте безопасный пароль, соответствующий требованиям DISA STIG, чтобы усилить защиту сервера Veeam Backup & Replication.
OTP для администратора и офицера безопасности Veeam: сгенерируйте и настройте одноразовые пароли для ролей администратора и офицера безопасности (Security Officer). Несмотря на то, что для корректной работы OTP требуется точное время, доступ к интернету для их проверки не нужен, что позволяет использовать систему в изолированных средах.
Настройка кластера
Создание кластера и настройка сети - укажите сетевые параметры для надёжной связи с другими компонентами и резервным сервером.
Задайте сетевые параметры основного и резервного узлов. Убедитесь, что оба узла кластера находятся в одной IP-подсети — на этапе бета-тестирования это обязательное условие.
После этого начнется процесс создания и конфигурации кластера.
Если основной узел не отвечает, вы можете инициировать операцию переключения (failover), чтобы ввести в работу резервный узел.
Важным преимуществом такого подхода является то, что нет необходимости импортировать резервную копию конфигурации, заново создавать задания, импортировать бэкапы или повторно вводить учётные данные — Veeam Backup & Replication продолжает работать без перебоев. Мы ещё увидим, какие дополнительные возможности появятся в финальном релизе, запланированном на конец этого года. Возможно, будут добавлены новые функции, но даже на текущем этапе это крайне полезная возможность, которая экономит массу времени в аварийной ситуации.
Хотя процесс переключения не автоматизирован и должен запускаться вручную авторизованным пользователем, появление команд PowerShell в будущих версиях откроет возможность создания и интеграции собственной логики автоматизации — например, с использованием узла-наблюдателя (witness node).
Известный блоггер Эрика Слуф опубликовал интересное видео, посвященное обеспечению высокой доступности и восстановлению после сбоя в кластере NSX-T Management Cluster.
В этом видео Эрик демонстрирует эти концепции в действии, рассматривая различные сценарии отказов и подробно обсуждая стратегии аварийного восстановления. Вы можете получить копию оригинального файла Excalidraw и презентационные слайды в форматах PDF и PowerPoint на GitHub.
Введение
Поддержание доступности кластера управления NSX-T критически важно для обеспечения стабильности и производительности вашей виртуализованной сетевой среды. Далее будут рассмотрены стратегии обеспечения высокой доступности (HA) управляющих компонентов NSX-T, а также описан процесс восстановления при сбоях и лучшие практики для аварийного восстановления.
Обзор кластера управления NSX-T
Кластер управления NSX-T обычно состоит из трех узлов. Такая конфигурация обеспечивает избыточность и отказоустойчивость. В случае отказа одного узла кластер сохраняет кворум, и нормальная работа продолжается. Однако отказ двух узлов может нарушить работу управления, требуя оперативных действий по восстановлению.
Высокая доступность в кластере управления NSX-T
1. Поддержание кворума
Для поддержания кворума кластер управления должен иметь как минимум два из трех узлов в рабочем состоянии. Это обеспечивает доступность интерфейса NSX Manager и связанных сервисов. Если один узел выходит из строя, оставшиеся два узла могут продолжать общение и управление средой, предотвращая простой.
2. Отказы узлов и их влияние
Отказ одного узла: кластер продолжает работать нормально с двумя узлами.
Отказ двух узлов: кластер теряет кворум, интерфейс NSX Manager становится недоступным. Управление через CLI и API также будет невозможно.
Стратегии восстановления
Когда большинство узлов выходит из строя, требуются оперативные действия для восстановления кластера до функционального состояния.
1. Развертывание нового управляющего узла
Разверните новый управляющий узел как четвертый член существующего кластера.
Используйте команду CLI detach node <node-uuid> или API-метод /api/v1/cluster/<node-uuid>?action=remove_node для удаления неисправного узла из кластера.
Эту команду следует выполнять с одного из здоровых узлов.
2. Деактивация кластера (по желанию)
Выполните команду deactivate cluster на активном узле для формирования кластера из одного узла.
Добавьте новые узлы для восстановления кластера до конфигурации из трех узлов.
Лучшие практики для аварийного восстановления
1. Регулярные резервные копии
Планируйте регулярные резервные копии конфигураций NSX Manager для быстрой восстановления.
Храните резервные копии в безопасном месте и обеспечьте их доступность в случае аварийного восстановления.
2. Географическая избыточность
Развертывайте NSX Manager на нескольких площадках для обеспечения географической избыточности.
В случае отказа одной площадки другая может взять на себя операции управления с минимальными перебоями.
Проактивный мониторинг
Используйте встроенные инструменты мониторинга NSX-T и интегрируйте их с решениями сторонних производителей для постоянного мониторинга состояния кластера управления.
Раннее обнаружение проблем может предотвратить серьезные сбои и уменьшить время простоя.
Площадка аварийного восстановления
Подготовьте площадку для аварийного восстановления с резервными NSX Manager, настроенными для восстановления из резервных копий.
Такая настройка позволяет быстро восстановить и обеспечить непрерывность работы в случае отказа основной площадки.
Заключение
Обеспечение высокой доступности и аварийного восстановления вашего кластера управления NSX-T необходимо для поддержания надежной и устойчивой виртуальной сетевой среды. Следуя лучшим практикам управления узлами, развертывания географически избыточной конфигурации и регулярного создания резервных копий, вы можете минимизировать время простоя и обеспечить быстрое восстановление после сбоев.
Для более детального изучения технических деталей ознакомьтесь с следующими ресурсами:
У Brock Peterson есть хорошая подборка статей о решении VMware Aria Operations (ранее этот продукт назывался vRealize Operations или vROPs). Сегодня мы посмотрим на то, как работает кластер vROPs/Aria с точки зрения основных архитектур отказоустойчивости - Standalone, High Availability (HA) и Continuous Availability (CA). Официальная документация на эту тему находится тут, а мы начнем с некоторых понятий:
Primary Node (основной узел) - начальный и единственный обязательный узел в Aria Ops. Все остальные узлы управляются основным узлом. В установке с одним узлом основной узел выполняет все функции.
Data Node (дата-узел) - на этих узлах установлены адаптеры, они собирают данные и выполняют анализ. В крупных развертываниях адаптеры обычно устанавливаются только на дата-узлах, чтобы основной узел и реплики могли сосредоточиться на управлении кластером.
Replica Node (реплика) - высокая доступность (HA) и непрерывная доступность (CA) Aria Ops требует преобразования дата-узла в реплику. Это копия основного узла, которая используется в случае его отказа.
Witness Node (свидетель) - непрерывная доступность (CA) Aria Ops требует наличие узла-свидетеля. Свидетель выступает в качестве арбитра при принятии решений о доступности Aria Ops.
Remote Collectors (удаленные сборщики) - распределенные развертывания могут требовать удаленных сборщиков (RC), которые могут обходить брандмауэры, взаимодействовать с удаленными источниками данных, снижать нагрузку на каналы передачи данных между центрами обработки данных или уменьшать нагрузку на кластер аналитики Aria Ops. Узлы RC только собирают объекты для инвентаризации, без хранения данных или выполнения анализа. Кроме того, удаленные сборщики могут быть установлены на другой операционной системе, чем остальные узлы кластера.
Важно отметить, что основные узлы и реплики также являются дата-узлами. Кластер аналитики (Analytics Cluster) включает все основные узлы, реплики и дата-узлы. Кластер Aria Ops включает кластер аналитики и любые узлы удаленных сборщиков.
Вне кластера Aria Ops также могут быть Cloud Proxies (CP). Первоначально они назывались Remote Collectors для развертываний vROps Cloud, но потом они были доработаны для полного замещения RC. Рекомендации по их сайзингу можно найти здесь. Отдельное развертывание может выглядеть следующим образом:
Вы можете построить кластер Aria Ops несколькими способами: автономный (Standalone), с высокой доступностью (HA) или с непрерывной доступностью (CA).
Начнем с базового варианта (изображенного выше), автономные варианты выглядят следующим образом:
Single Primary Node Cluster (кластер с одним основным узлом) - в этом развертывании ваш основной узел Aria Ops будет выполнять все функции: административный интерфейс, продуктовый интерфейс, REST API, хранение данных, сбор и аналитика. Такие развертывания часто используются для пробных версий или пилотных проектов (proof-of-concept). Сайзинг основных узлов зависит от количества объектов и метрик, которые они будут обрабатывать, подробности можно найти здесь.
Кластеры с несколькими узлами (Multi-Node Clusters):
Основной узел и как минимум один дата-узел, но может включать и до 16 дата-узлов. Дата-узлы могут выполнять все функции, которые выполняет основной узел, кроме обслуживания Admin UI. Они часто используются для разгрузки основного узла. Обратите внимание, что основной узел также является дата-узлом.
Основной узел и как минимум один облачный прокси (CP), но может включать и до 60 CP. Ранее известные как удаленные сборщики (RC), они используются для обхода брандмауэров, получения данных из удаленного источника, уменьшения пропускной способности между центрами обработки данных и других задач. Они только собирают метрики, не хранят данные и не выполняют анализ данных. RC являются частью кластера Aria Ops, тогда как CP не являются частью кластера.
Автономные варианты визуально выглядят следующим образом.
Существует несколько лучших практик при создании кластеров Aria Ops, например: развертывайте узлы в одном и том же кластере vSphere в одном датацентре и добавляйте только один узел за раз, позволяя ему завершить процесс перед добавлением следующего узла. Подробнее о лучших практиках можно узнать здесь.
Клиенты часто используют балансировщик нагрузки перед своим кластером Aria Ops, чтобы избежать перебоев в обслуживании в случае потери дата-узла. Этот балансировщик нагрузки может указывать на основной узел или любой из дата-узлов, так как все они обслуживают пользовательский интерфейс. Однако если основной узел выйдет из строя, произойдет потеря данных, и потребуется восстановление кластера.
В версии vRealize Operations 6.0 была введена функция HA, обеспечивающая некоторую защиту от потери аналитического узла (основной узел, реплика узел или дата-узел). Следует отметить, что Aria Ops HA не является стратегией аварийного восстановления (DR), но обеспечивает некоторую защиту от потери данных. Как и для кластеров без HA, мы просто добавляем узел реплики, получая следующие конфигурации:
Основной узел и реплика
Основной узел, реплика и до 16 дата-узлов
Основной узел, реплика и до 60 облачных прокси (CP)
Основной узел, реплика, до 16 дата-узлов и до 60 CP
Как описано здесь, Aria Ops HA создает копию основного узла, называемую репликой, и защищает кластер аналитики от потери дата-узла. Aria Ops использует базу данных PostgreSQL, распределенную между всеми дата-узлами (включая основной узел и реплики) для хранения всех данных, поэтому если мы потеряем основной узел, узел реплики будет повышен до основного, и мы продолжим работу без потери данных. Если мы потеряем дата-узел, эти данные также доступны на основных/реплика узлах (эта схема похожа на RAID5), поэтому потери данных не будет. Если мы потеряем более одного дата-узла, произойдет потеря данных.
Лучшие практики для развертывания кластера Aria Ops HA можно найти здесь. В итоге, ваш кластер Aria Ops HA будет выглядеть примерно так:
Вы можете разместить перед вашим кластером Aria Ops HA балансировщик нагрузки, как и раньше, указывающий на ваш основной узел, реплику и дата-узлы.
В версии Aria Ops 8.0 были введены функции непрерывной доступности (CA) и концепция доменов отказа. Можно сказать, что Aria Ops CA - это Aria Ops HA с репликой в другом физическом расположении, а также с парными дата-узлами и узлом Witness, чтобы отслеживать все процессы.
Aria Ops CA защищает нас от потери целого домена отказа, например, всего датацентра. Как описано здесь, с CA данные, хранящиеся в основном узле и дата-узлах в домене отказа 1, постоянно синхронизируются с узлом реплики и дата-узлами в домене отказа 2. Aria Ops CA требует как минимум один дата-узел в дополнение к основному узлу, и они должны быть парными, то есть дата-узел в домене отказа 1 требует дата-узел в домене отказа 2.
Существует третий узел, называемый свидетелем (Witness), который ни собирает, ни хранит данные. Он определяет, в каком домене отказа должен работать кластер Aria Ops. Его можно представить как диспетчер трафика, маршрутизирующий трафик на основе состояния основного узла Aria Ops.
В идеале, у вас должно быть три физических локации, но домены отказа могут быть определены по вашему усмотрению. Архитектура Aria Ops CA предоставляет вам наибольшую доступную сегодня защиту. Аналогично автономным кластерам и кластерам HA, клиенты могут разместить перед своим кластером Aria Ops CA балансировщик нагрузки, чтобы направлять пользователей к активному кластеру.
Недавно компания VMware выпустила обновленную версию платформы виртуализации vSphere 8 Update 2, где было сделано много интересных изменений. В частности, несколько поменялся интерфейс механизма vSphere Cluster Services (vCLS).
Напомним, что VMware High Availability (HA) и DRS при активации создают системные виртуальные машины vCLS в vSphere. Это обязательно, так как эти ВМ развертываются на каждом кластере vSphere после обновления vCenter Server до версии v7.0 Update 2 или более поздней. Теперь интерфейс vSphere Cluster Services изменился с выпуском vSphere 8.0 U2, про который Дункан Эппинг рассказывает в своем видео:
Начиная с vSphere 7.0 Update 2, автоматически создается и применяется новое правило anti-affinity. Это правило гарантирует, что каждые 3 минуты проводится проверка, не расположены ли несколько ВМ vCLS на одном и том же хранилище данных. Если это так, правило инициирует операцию storage vMotion и перераспределяет эти ВМ по разным хранилищам.
Когда хранилище данных, на котором расположены ВМ vCLS, переводится в режим обслуживания, вам нужно вручную применить Storage vMotion к машинам vCLS, чтобы переместить их в новое место, или перевести кластер в режим Retreat Mode.
Режим Retreat Mode позволяет отключить службу vSphere Clustering Service для автоматического удаления виртуальных машин-агентов. Это полезно, когда вам нужно выполнить задачи по техническому обслуживанию инфраструктуры, в частности хранилищ, чтобы эти вспомогательные ВМ вам не мешали.
Ранее Retreat Mode был доступен только через расширенную конфигурацию, а теперь его можно включать через пользовательский интерфейс, начиная с vSphere 8.0 U2. Для этого откройте vSphere Client, выберите ваш кластер > Configure > General (в разделе vSphere Cluster Service), далее нажмите Edit vCLS mode:
Вчера мы писали о новых возможностях январского релиза облачного решения VMware Aria Operations. Одной из них стала высокая доступность средств мониторинга приложений High Availability for Application Monitoring, которую можно рассмотреть несколько подробнее.
Многие пользователи уже применяют решение Telegraf в VMware Aria Operations, выполняющее функции мониторинга доступности приложений и зависящее от компонентов Cloud Proxies, через которые происходит сбор данных от эндпоинтов. Сам мониторинг происходит через ARC-адаптеры приложений, которые ранее не поддерживали группы коллекторов, а Cloud Proxy был единой точкой отказа для функций application monitoring. Поэтому при выходе из строя Cloud Proxy данные от эндпоинтов не могли попадать в VMware Aria Operations.
Теперь же мониторинг приложений работает с помощью механизма Collector Groups, в которые объединены Cloud Proxy, поэтому при падении одного из них метрики будут передаваться в другие инстансы.
Первый шаг в интерфейсе - это создание Collector Group. Здесь были сделаны улучшения по добавлению новых групп и включению/выключению механизма высокой доступности из UI:
Здесь можно устанавливать используемый виртуальный IP, а также отмечать объекты Cloud Proxies, которые добавляются. Как только мы добавили новую группу, мы можем фильтровать по этим группам, когда они отображаются списком.
Можно группировать прокси по группам коллекторов и просматривать их в рамках групп, либо показывать все прокси без групп:
Также есть механизм по проверке конфигураций, если были внесены изменения в составе Collector Group. После того, как прокси были добавлены или удалены, становится активной опция "Retry Cloud Proxy Configuration", а также возможность активации/деактивации data persistence:
Также для использования HA нужно развертывание агента Telegraf. Старые версии агента не могут обрабатывать новые изменения, поэтому требуется повторное их развертывание с привязкой их к группам коллекторов. Поэтому при установке агента мы выбираем, будет ли агент обеспечивать функции высокой доступности, и если будет - то для какой группы с включенным HA он будет назначен:
После того, как мы задали все конфигурации, требуется время на то, чтобы развернуть агенты и создать все необходимые связи с возможностями восстановления после сбоя. В случае сбоя может потребоваться до трех холостых циклов сбора данных, чтобы сработало восстановление, и данные продолжили собираться. В большинстве случаев это происходит быстро, но если включена возможность data persistence, то можно потерять один цикл сбора метрик.
Больше подробностей об облачном решении VMware Aria Operations можно узнать на этой странице.
Многие из вас используют или интересуются решением StarWind Virtual SAN, которое является сейчас одним из основных продуктов на рынке для организации отказоустойчивых кластеров хранилищ (а еще и самым технологически продвинутым). Сегодня мы поговорим об узле Witness node в кластерах и о том, как он помогает защитить его от массовых сбоев в виртуальной среде.
Как знают многие администраторы, еще в прошлом году в ESXi 7 Update 2 компания VMware стала убирать различные настройки из основного конфигурационного файла esx.conf. Кстати, и не только оттуда. Например, раньше глобальные настройки FDM (он же HA - High Availability) хранились в файле /etc/opt/vmwware/fdm/fdm.cfg. Теперь их там тоже нет - они переехали во внутреннее хранилище ConfigStore, работать с которым нужно с помощью утилиты командной строки configstorecli.
То же самое произошло и с NTP - теперь настройки времени, хранящиеся в /etc/ntp.conf (для NTP) и /etc/ptp.conf (для PTP), недоступны для редактирования через файлы конфигураций. Кстати, если вы не знаете, чем NTP отличается от PTP, у нас есть отличная статья на эту тему (а вот тут - о поддержке PTP в vSphere 7 Update 2).
Более того, теперь все файлы каталога /etc помечены как только для чтения и не сохраняют своих изменений при перезагрузке!
Так что работать с большинством настроек теперь нужно через ConfigStore. В частности, для NTP и PTP есть 2 основных команды, которые взаимодействуют с ConfigStore для конфигурации времени:
Получение настроек времени
# esxcli system ntp get
# esxcli system ptp get
Установка настроек времени
# esxcli system ntp set
# esxcli system ptp set
Если вы хотите узнать список всех конфигурационных файлов, которыми теперь заведует ConfigStore, можно выполнить следующую команду в консоли ESXi:
Компания VMware анонсировала новую версию продукта VMware HCX 4.3, предназначенного для миграции с различных онпремизных инфраструктур (на базе как vSphere, так и Hyper-V или KVM) в облако на платформе VMware vCloud. Напомним, что о возможностях версии 4.2 этого продукта мы писали вот тут.
Давайте посмотрим на новые возможности HCX 4.3:
1. Переход на PostgreSQL
Теперь HCX использует БД PostgreSQL вместо устаревших баз данных, использовавшихся ранее. Для пользователя переход произойдет незаметно, а сами данные в фоновом режиме будут перенесены на новую платформу.
2. Улучшения HCX Network Extension
Теперь для виртуальных модулей Network Extension появились функции высокой доступности (high availability). Так как сервис Network Extension является критичной частью HCX, нарушения в работе которого могут привести к серьезным проблемам с функционированием, то теперь на уровне виртуальных модулей (Virtual Appliance) есть функции HA, которые работают в режиме active/standby. В случае сбоя переключение на запасной узел происходит автоматически.
Диаграмма ниже показывает, как работают виртуальные модули NE, которые формируют пары на каждой из площадок, а во время нормальных операций трафик использует active-туннель между модулями. Другой туннель между standby-модулями также поддерживается, но трафик по нему не идет. На него происходит переключение в случае сбоя основного канала.
HA group 1 и HA group 2 имеют независимые механизмы хартбитов, чтобы мониторить состояние виртуальных модулей.
3. Улучшения OS Assisted-миграций
OS Assisted Migration (OSAM) - это режим миграции виртуальных машин из не-vSphere окружений, таких как KVM и Hyper-V, на платформу vSphere. Здесь было сделано несколько важных улучшений:
Поддержка новых гостевых ОС - теперь HCX поддерживает миграцию ВМ на базе RHEL 8.x (64-bit) и CentOS 8.x (64-bit) в окружениях KVM на vSphere. Кроме того, можно мигрировать RHEL 8.x (BIOS/GEN-1 & UEFI/GEN-2) и CentOS 8.x (BIOS/GEN-1 & UEFI/GEN-2) из виртуальных машин Hyper-V.
Совместимость HCX OSAM для vSphere и Cloud Director - теперь при миграции поддерживается связка продуктов VMware vSphere 7.0 U3 и VMware Cloud Director 7.0 U3.
4. Улучшения юзабилити
Устранен лимит на 15 символов для имен хостов ВМ на базе MS Windows при кастомизации гостевой ОС.
Возможность изменять Compute Profile в режиме OSAM. Ранее надо было явно указывать целевой датастор в профиле, теперь же HCX обнаруживает набор датасторов, которые доступны для репликации в кластер. Также происходит валидация, что Sentinel Data Receiver (SDR) имеет доступ к датастору, указанному пользователем.
Более подробно о продукте VMware HCX 4.3 можно почитать на этой странице.
Весной этого года компания VMware выпустила большое обновление серверной платформы виртуализации VMware vSphere 7 Update 2, включающее в себя множество новых возможностей и улучшений. Основные улучшения знает большинство администраторов, так как об этом писали достаточно подробно. Но есть и несколько небольших, но важных изменений, знать про которые было бы очень полезно. Давайте на них посмотрим...
Компания StarWind Software, известная многим из вас как ведущий производитель программно-аппаратных хранилищ под виртуализацию VMware vSphere и Microsoft Hyper-V, запустила новый продукт StarWind SAN & NAS, который предназначен для создания хранилищ на основе севреров с установленным там гипервизором. В качестве платформы StarWind SAN & NAS использует Linux...
Компания VMware выпустила большое обновление серверной платформы виртуализации VMware vSphere 7 Update 2, включающее в себя множество новых возможностей и улучшений. Напомним, что прошлый релиз vSphere 7 Update 1 был выпущен в начале сентября прошлого года, так что времени прошло уже немало.
Нововведения второго пакета обновлений сконцентрированы в трех основных областях:
Давайте посмотрим на новые возможности vSphere 7 Update 2 более детально:
1. Инфраструктура AI и Developer Ready
На основе технологий, анонсированных в 2020 году, компании VMware и NVIDIA сделали совместный анонс платформы AI-Ready Enterprise Platform.
NVIDIA объединилась с VMware для виртуализации рабочих AI-нагрузок в VMware vSphere с помощью NVIDIA AI Enterprise. Это позволяет предприятиям разрабатывать широкий спектр решений для работы с искусственным интеллектом, таких, как расширенная диагностика в здравоохранении, умные предприятия для производства и обнаружение мошенничества в финансовых услугах.
NVIDIA предоставляет пользователям уникальный набор утилит и фреймворков для решения AI-задач на платформе VMware vSphere.
Решение AI Enterprise:
Поддерживает последние поколения GPU от NVIDIA в целях достижения максимальной производительности (до 20 раз лучше, чем в прошлом поколении).
Поддерживает NVIDIA GPUDirect RDMA for vGPUs.
Поддерживает разделение NVIDIA multi-instance GPU (MIG), что позволяет обеспечивать горячую миграцию виртуальных машин c vGPU на борту c помощью vMotion.
Посредством Distributed Resource Scheduler (DRS) обеспечивает автоматическую балансировку машин AI-инфраструктуры по хост-серверам.
Также появились и новые возможности в плане поддержки инфраструктуры контейнеров vSphere with Tanzu:
Интегрированная балансировка нагрузки на приложения посредством VMware NSX Advanced Load Balancer Essentials edition с поддержкой HA с использованием автоматизаций Kubernetes-native (подробнее об этом тут).
Сервисный кластер Tanzu Kubernetes Grid и Supervisor-кластер можно обновить до Kubernetes 1.19.
Улучшенная поддержка сторонних репозиториев, что повышает гибкость и безопасность.
2. Инфраструктурные улучшения и безопасность данных
В этой категории появились следующие новые возможности:
Новый vSphere Native Key Provider - механизм, который позволяет использовать защиту data-at-rest, такую как vSAN Encryption, VM Encryption и vTPM прямо из коробки.
Поддержка Confidential Containers для vSphere Pods, которые используют память AMD SEV-ES и CPU data encryption на платформах AMD EPYC.
Механизм ESXi Configuration Encryption, который использует оборудование Trusted Platform Module (TPM) для защиты ключей ESXi на хостах.
Техника ESXi Key Persistence, которая дает возможности для защиты данных data-at-rest на изолированных хостах.
Обновленные рекомендации vSphere Product Audit Guides, а также FIPS validation для сервисов vCenter Server.
3. Упрощение операций
Техника ESXi Suspend-to-Memory, которая позволяет еще проще обновлять хосты ESXi. Она доступна в комбинации с технологией ESXi Quick Boot. Виртуальные машины просто встают на Suspend в памяти ESXi, вместо эвакуации с хоста, а потом ядро гипервизора перезапускается и хост обновляется.
Оптимизации процессоров AMD EPYC CPU, что приводит к улучшению производительности.
Поддержка рабочих нагрузок Persistent Memory (PMEM) со стороны vSphere HA. Это позволяет техникам DRS initial placement и High Availability полноценно работать в кластере.
Новый функционал решения vSphere Lifecycle Manager with Desired Image Seeding, который позволяет автоматизировать обновление микрокода к желаемому состоянию:
Все фичи vSphere Lifecycle Manager теперь доступны для окружений vSphere with Tanzu.
Функция Desired image seeding позволяет реплицировать информацию о желаемой конфигурации с референсного хоста, экономя время администратора на настройку.
Функция vMotion Auto Scaling, которая позволяет автоматически подстраивать производительность в сетях 25, 40 и 100 Гбит.
Уменьшенное I/O latency и jitter для проброшенных напрямую (passthrough) сетевых адаптеров.
Улучшенная поддержка Virtual Trusted Platform Module (vTPM) для гостевых ОС Windows и популярных дистрибутивов Linux.
Улучшения VMware Tools, включая Guest Store - метод для распространения конфигураций и файлов между виртуальными машинами, а также драйверы Precision Clock drivers для службы Windows Time Service.
Многим из вас знакомы продукты компании StarWind, предназначенные для создания отказоустойчивых хранилищ под различные платформы виртуализации. Одним из лидеров отрасли является решение StarWind Virtual SAN, у которого есть множество функций хранения, обеспечения доступности и защиты данных. А сегодня мы поговорим еще об одном бизнесе компании StarWind - программно аппаратных комплексах для специальных задач...
Одной из новых возможностей VMware vSphere 7 U1 стала служба vSphere Clustering Service (vCLS), которая позволяет организовать мониторинг доступности хостов кластера vSphere, без необходимости зависеть от служб vCenter.
Как вы знаете, кластер HA/DRS очень зависит от постоянной доступности сервисов vCenter, который является критическим звеном виртуальной инфраструктуры. Поэтому для него организовывают такие сервисы, как vCenter Server High Availability (VCHA), но и они не идеальны. Также проблема наблюдается при масштабировании кластеров в больших окружениях, которые объединяют онпремизные и облачные площадки, где масштабируемость vCenter является серьезной проблемой.
Учитывая это, VMware придумала такую штуку - сажать на хосты кластера 3 служебных агентских виртуальных машины, составляющих vCLS Control Plane, которые отвечают за доступность кластера в целом:
Таких виртуальных машин три в кластере, где 3 или более хостов, и две, если в кластере два хоста ESXi. Три машины нужны, чтобы обеспечивать кворум (2 против 1) в случае принятия решения о разделении кластера.
Три этих виртуальных машин следят друг за другом и оповещают об этом кластерные службы vCenter:
Это самокорректирующийся механизм, что значит, что если одна из агентских машин становится недоступной или выключенной, то службы vCLS пытаются самостоятельно наладить работу ВМ или включить ее.
Есть 3 состояния служб vCLS:
Healthy – как минимум 1 агентская ВМ работает в кластере, чтобы обеспечить доступность кластера развертываются 3 ВМ для кворума.
Degraded – как минимум одна агентская машина недоступна, но DRS продолжает функционировать и исполнять свою логику. Такое может, например, произойти при передеплое служебных машин vCLS или после какого-то события, повлиявшего на их "включенность".
Unhealthy – логика DRS не выполняется (балансировка или размещение ВМ), так как vCLS control-plane недоступна (то есть ни одной агентской ВМ не работает).
Легковесные машины-агенты исполняются на хостах ESXi и лежат на общих хранилищах, если общие хранилища недоступны - то на локальных дисках. Если вы развернули общие хранилища после того, как собрали кластер DRS/HA (например, развернули vSAN), то рекомендуется перенести агентские ВМ с локальных хранилищ на общие.
Сама гостевая ОС агентских ВМ очень легковесная, используется Photon OS следующей конфигурации:
Диск в 2 ГБ - это тонкий диск, растущий по мере наполнения данными (thin provisioned). Эти машины не имеют своего нетворка, а также не видны в представлении Hosts and Clusters в клиенте vSphere.
Агентские ВМ можно увидеть в представлении VMs and Templates где есть папка vCLS:
Обратите внимание, написано, что для агентских ВМ управление питанием производится со стороны служб vCLS. Если вы попытаетесь выключить эти ВМ, то будет показано следующее предупреждение:
При переводе кластера в режим обслуживания vCLS сам заботится о миграции агентских ВМ с обслуживаемых серверов и возвращении их обратно. Для пользователя это происходит прозрачно. И, конечно же, лучше не выключать эти ВМ вручную и не переименовывать папки с ними.
Жизненный цикл агентских ВМ обслуживается со стороны vSphere ESX Agent Manager (EAM).
EAM отвечает за развертывание и включение агентских ВМ, а также их пересоздание, если с ними что-то произошло. В анимации ниже показано, как EAM восстанавливает ВМ, если пользователь выключил и/или удалил ее:
Важный момент для разработчиков сценариев PowerCLI - это необходимость обрабатывать такие ВМ, чтобы случайно не удалить их. Например, ваш скрипт ищет неиспользуемые и забытые ВМ, а также изолированные - он может по ошибке принять машины vCLS за таковые и удалить, поэтому их надо исключать в самом сценарии.
В интерфейсе vSphere Client список агентских ВМ можно вывести в разделе "Administration > vCenter Server Extensions > vSphere ESX Agent Manager".
У агентских ВМ есть свойства, по которым разработчик может понять, что это они. В частности:
ManagedByInfo
extensionKey == "com.vmware.vim.eam"
type == "cluster-agent"
ExtraConfig keys
"eam.agent.ovfPackageUrl"
"eam.agent.agencyMoId"
"eam.agent.agentMoId"
Основное свойство, по которому можно идентифицировать агентскую ВМ, это HDCS.agent, установленное в значение "true". В Managed Object Browser (MOB) выглядит это так:
Ну и напоследок - небольшое демо технологии vSphere Clustering Service:
На днях пришла пара важных новостей о продуктах компании StarWind Software, которая является одним из лидеров в сфере производства программных и программно-аппаратных хранилищ для виртуальной инфраструктуры.
StarWind HCA All-Flash
Первая важная новость - это выпуск программно-аппаратного комплекса StarWind HyperConverged Appliance (HCA) All-Flash, полностью построенного на SSD-накопителях. Обновленные аппаратные конфигурации StarWind HCA, выполненные в форм-факторе 1 или 2 юнита, позволяют добиться максимальной производительности хранилищ в рамках разумной ценовой политики. Да, All-Flash постепенно становится доступен, скоро это смогут себе позволить не только большие и богатые компании.
Решение StarWind HCA - это множество возможностей по созданию высокопроизводительной и отказоустойчивой инфраструктуры хранилищ "все-в-одном" под системы виртуализации VMware vSphere и Microsoft Hyper-V. Вот основные высокоуровневые возможности платформы:
Поддержка гибридного облака: кластеризация хранилищ и active-active репликация между вашим датацентром и любым публичным облаком, таким как AWS или Azure
Функции непрерывной (Fault Tolerance) и высокой доступности (High Availability)
Безопасное резервное копирование виртуальных машин
Проактивная поддержка вашей инфраструктуры специалистами StarWind
И многое, многое другое
Сейчас спецификация на программно-аппаратные модули StarWind HCA All-Flash выглядит так:
После развертывания гиперконвергентной платформы StarWind HCA она управляется с помощью единой консоли StarWind Command Center.
Ну и самое главное - программно-аппаратные комплексы StarWind HCA All-Flash полностью на SSD-дисках продаются сегодня, по-сути, по цене гибридных хранилищ (HDD+SSD). Если хотите узнать больше - обращайтесь в StarWind за деталями на специальной странице. Посмотрите также и даташит HCA.
Давайте посмотрим, что нового появилось в StarWind Virtual SAN V8 for Hyper-V:
Ядро продукта
Добавлен мастер для настройки StarWind Log Collector. Теперь можно использовать для этого соответствующее контекстное меню сервера в Management Console. Там можно подготовить архив с логами и скачать их на машину, где запущена Management Console.
Исправлена ошибка с заголовочным файлом, который брал настройки из конфига, но не существовал на диске, что приводило с падению сервиса.
Улучшен вывод событий в файлы журнала, когда в системе происходят изменения.
Улучшена обработка ответов на команды UNMAP/TRIM от аппаратного хранилища.
Добавлена реализация процессинга заголовка и блога данных дайждестов iSCSI на процессорах с набором команд SSE4.2.
Максимальное число лог-файлов в ротации увеличено с 5 до 20.
Механизм синхронной репликации
Процедура полной синхронизации была переработана, чтобы избежать перемещения данных, которые уже есть на хранилище назначения. Делается это путем поблочного сравнения CRC и копирования только отличающихся блоков.
Исправлена ошибка падения сервиса в случае выхода в офлайн партнерского узла при большой нагрузке на HA-устройство.
Значение по умолчанию пинга партнерского узла (iScsiPingCmdSendCmdTimeoutInSec) увеличено с 1 до 3 секунд.
Исправлена ошибка с утечкой памяти для состояния, когда один из узлов был настроен с RDMA и пытался использовать iSER для соединения с партнером, который не принимал соединений iSER.
Нотификации по электронной почте
Реализована поддержка SMTP-соединений через SSL/STARTTLS.
Добавлена возможность аутентификации на SMTP.
Добавлена возможность проверки настроек SMTP путем отправки тестового сообщения.
Компоненты VTL и Cloud Replication
Список регионов для всех репликаций помещен во внешний файл JSON, который можно просто обновлять в случае изменений на стороне провайдера.
Исправлена обработка баркодов с длиной, отличающейся от дефолтной (8 символов).
Исправлена ошибка падения сервиса при загрузке tape split из большого числа частей (тысячи).
Исправлены ошибки в настройках CloudReplicator Settings.
Модуль StarWindX PowerShell
Обновился скрипт AddVirtualTape.ps1, был добавлен учет параметров, чувствительных к регистру.
Для команды Remove-Device были добавлены опциональные параметры принудительного отсоединения, сохранения сервисных данных и удаления хранимых данных на устройстве.
Добавлен метод IDevice::EnableCache для включения и отключения кэша (смотрите примеры FlashCache.ps1 и FlushCacheAll.ps1).
VTLReplicationSettings.ps1 — для назначения репликации используется число, кодирующее его тип.
Свойство "Valid" добавлено к HA channel.
Сценарий MaintenanceMode.ps1 — улучшенная обработка булевых параметров при исполнении сценария из командной строки.
Тип устройства LSFS — удален параметр AutoDefrag (он теперь всегда true).
Средство управления Management Console
Небольшие улучшения и исправления ошибок.
Скачать полнофункциональную пробную версию StarWind Virtual SAN for Hyper-V можно по этой прямой ссылке. Release Notes доступны тут.
Таги: StarWind, Update, Storage, iSCSI, HCA, Hardware, SSD, HA, DR
У компании VMware вышла полезная многим администраторам решения vRealize Operations (vROPs) онлайн-утилита для сайзинга управляющей инфраструктуры - vRealize Operations Sizing Tool. Она будет полезна администраторам и консультантам, которые планируют развертывание инфраструктуры vROPs и подбирают для этого оборудование и необходимые мощности.
В случае прикидочного расчета нужно просто выбрать версию vRealize Operations Manager и указать тип сайзинга Basic:
Это даст обобщенные требования к оборудованию при минимальном вводе данных. В basic-режиме вы просто задаете параметры своей виртуальной инфраструктуры, условия хранения данных на серверах vROPs и планируемый рост инфраструктуры:
Также параметр High Availability удвоит число необходимых узлов за счет введения резервных.
Итогом будут рекомендации по числу и конфигурации узлов, которые будут обслуживать сервисы мониторинга vROPs (для этого надо нажать на ссылку View Recommendations):
Полученный отчет можно выгрузить в PDF-формат. Кстати, если нажмете на вкладку Environment, то можно будет скорректировать данные, не начиная процесс с начала.
Если же вы выберете режим Advanced для более точного сайзинга, то в самом начале у вас запросят несколько больше данных о вашей виртуальной инфраструктуре:
После параметров объектов vCenter вы сможете задать имеющиеся или планируемые Management Packs от сторонних производителей или самой VMware (и число отслеживаемых объектов в них):
Если же у вас уже есть инфраструктура vRealize Operations, то vRealize Operations Sizing Tool - это хорошее средство, чтобы проверить, что вы правильно подобрали конфигурацию узлов под vROPs.
Для этого надо пойти в раздел Administration > History > Audit > System Audit и там посмотреть итоговое настроенное число объектов (Objects) и метрик (Metrics):
После этого вы можете вбить это число в разделе Other Data Sources и получить расчет параметров сервера, который более-менее должен сходиться с вашей конфигурацией узлов:
VMware UAG представляет собой шлюз для доступа к инфраструктуре Workspace ONE и Horizon. Шлюз используется для безопасного доступа внешних авторизованных пользователей ко внутренним ресурсам рабочей области Workspace ONE, а также виртуальным десктопам и приложениям Horizon.
Напомним, что о прошлой версии Unified Access Gateway 3.3 мы писали вот тут.
Давайте посмотрим, что нового появилось в UAG 3.4:
1. Обеспечение собственной высокой доступности (High Availability).
Как и другие компоненты инфраструктуры VDI, решение UAG теперь поддерживает механизм обеспечения собственной высокой доступности.
Делается это средствами виртуального IP-адреса и Group ID, что позволяет балансировать трафик на порту 443 для более чем 10 тысяч одновременных подключений. Это позволяет снизить операционные затраты на обслуживание таких сервисов, как VMware Horizon 7, Web Reverse Proxy, Per-App Tunnel и VMware Content Gateway.
2. Механизм мониторинга Session Statistic Monitoring для оконечных сервисов.
Теперь с помощью этих функций в административной консоли UAG можно в реальном времени наблюдать за статистиками активных и неактивных сессий, неудачными попытками входа, сессиями протоколов Blast и PCoIP, туннелями и прочими параметрами. Это позволит грамотнее планировать балансировку пользовательских сессий.
3. Режим Cascade Mode для поддержки Horizon 7.
Для организаций, где требуется использование двухслойного DMZ, сервер UAG может работать в каскадном режиме (Cascade Mode). В этом случае внешний сервер UAG работает как Web Reverse Proxy для интернет-соединений пользователей, а внутренний - как Horizon Edge Service.
4. Ограничение доступа к службам Amazon Web Services.
Теперь с помощью UAG можно лимитировать доступ к облачным ресурсам AWS в целях разграничения доступа. В этом случае Unified Access Gateway можно импортировать в облако Amazon EC2, зарегистрировать как Amazon Image Machine (AMI) и развернуть с помощью сценария PowerShell.
5. Поддержка custom thumbprints.
Custom thumbprints позволяют использовать разные сертификаты для соединений Blast TCP и VMware Tunnel. Это можно сделать в консоли UAG или через PowerShell INI.
6. Нативная поддержка Horizon 7.
В консоли Horizon Administrator в дэшборде System Health теперь отображаются детали о зарегистрированных модулях VMware Unified Access Gateway для версии 3.4 и более поздних:
Скачать VMware Unified Access Gateway 3.4 можно по этой ссылке.
Возможность создания внешнего PSC появилась в версии vSphere 6.0, а еще в vSphere 5.1 компания VMware предоставила возможность размещать отдельные компоненты, такие как VMware Update Manager (VUM) или vCenter Server Database (VCDB) на отдельных серверах. Это привело к тому, что средства управления виртуальной инфраструктурой можно было развернуть аж на 6 серверах, что рождало проблемы интеграции, обновления и сложности обслуживания.
Когда VMware предложила модель с внешним PSC инфраструктура свелась всего к двум узлам сервисов vCenter. PSC обслуживает инфраструктуру SSO (Single Sign-On), а также службы лицензирования, тэгов и категорий, глобальных прав доступа и кастомных ролей. Помимо этого PSC отвечает за сертификаты данного SSO-домена.
В то время, как службы PSC принесли гибкость развертывания, они же принесли и сложность обслуживания, так как для них нужно было обеспечивать отдельную от vCenter процедуру отказоустойчивости в инфраструктуре распределенных компонентов vCenter Enhanced Linked Mode (ELM).
Еще в vSphere 6.7 и vSphere 6.5 Update 2 была введена поддержка режима ELM для Embedded PSC, поэтому с внедренным PSC уже не требуется обеспечивать отказоустойчивость дополнительных узлов, балансировку нагрузки, а также их обновление. Теперь можно обеспечивать доступность узлов vCenter посредством технологии vCenter High Availability.
Поэтому уже сейчас можете использовать vCenter Server Converge Tool для миграции внешних PSC на Embedded PSC виртуального модуля vCenter Server Appliance. А возможности развернуть внешние PSC в следующих версиях vSphere уже не будет.
Таги: VMware, vSphere, HA, vCenter, PSC, Update, vCSA
Мы уже писали о новых возможностях платформы виртуализации VMware vSphere 6.7 Update 1, которая стала доступна для загрузки совсем недавно. Сегодня мы остановимся на отдельных новых функциях управляющего сервера VMware vCenter Server 6.7 Update 1 и его клиента vSphere Client 6.7 U1 на базе технологии HTML 5, который стал полнофункциональным и заменил ушедший в прошлое Web Client.
Давайте посмотрим, что нового появилось в VMware vCenter Server 6.7 Update 1:
1. Улучшенные возможности поиска.
Теперь при поиске различных объектов можно использовать строковый параметр и различные фильтры (например, тэги, кастомные атрибуты и состояние питания ВМ). Также очень удобная функция - это возможность сохранить результаты поиска:
2. Темная тема vSphere Client.
Об этой функции мы уже упоминали - это один из главных запросов администраторов vSphere, которые любят поуправлять виртуальной инфраструктурой в темноте.
3. Утилита vCenter Server Converge Tool.
Эта новая утилита позволяет смигрировать внешний сервер Platform Services Controller (PSC) на простой в управлении embedded PSC. Проблема заключалась в том, что ранее пользователи использовали внешний PSC, поскольку он поддерживал Enhanced Linked Mode (ELM). И несмотря на то, что внедренный PSC стал поддерживать ELM еще в vSphere 6.7 и vSphere 6.5 Update 2, многие пользователи еще с предыдущих версий поддерживают комплексную инфраструктуру внешних PSC с репликацией между площадками.
Сейчас все стало проще - утилита vCenter Server Converge Tool устанавливает embedded PSC на vCenter Server Appliance (vCSA), после чего налаживает канал репликации с оставшимися внешними PSC. После того, как эта процедура пройдет на всех площадках, вы сможете отключить внешние PSC, а встроенный механизм vCenter HA сам настроится на работу с внедренными PSC.
Утилита vCenter Server Converge Tool работает из командной строки (команда vcsa-converge-cli) и поставляется в комплекте с установщиком vCSA. Ее можно запускать в ОС Windows, macOS и Linux, а конфигурируется она через файл в формате JSON:
Надо понимать, что теперь Embedded PSC - это рекомендуемый способ развертывания инфраструктуры vCenter:
4. Функции Embedded Domain Repoint.
vCenter Server с компонентом embedded PSC с помощью функции Domain Repoint теперь можно перенаправить на другой домен vSphere SSO (это позволяет более гибко распределять и разделять домены SSO в корпоративной инфраструктуре). Ранее это было сделано только для внешних SSO, а теперь доступно и для vCSA.
5. Улучшения vSphere 6.7 Update 1 vCenter High Availability.
Функции vCenter HA были введены еще в vSphere 6.5. Теперь эти возможности были доработаны - вместо рабочих процессов basic и advanced появился единый и простой workflow. Он включает в себя три стадии:
Создание vSphere SSO credentials для управление сервером vCenter и всей инфраструктурой.
Настройки ресурсов для пассивного узла и узла Witness, включая вычислительные ресурсы, хранилище и сеть.
Настройки IP для пассивного узла и узла Witness.
Также в процессе настройки автоматически создается клон активного vCenter для создания пассивного узла и Witness - для этого лишь нужно ввести учетные данные vSphere SSO.
Во время апгрейда автоматически обнаруживаются настройки vCHA, поэтому при обновлении на новую версию не требуется разбивать кластер серверов vCenter. Это учитывает мастер обновления и накатывает апдейт.
6. Интерфейс REST API для VCHA.
Для механизма vCenter High Availability стал доступен API, который позволяет управлять кластером vCenter:
7. Улучшения Content Library.
Теперь OVA-шаблоны можно импортировать из HTTPS-источника или с локального хранилища. Также содержимое OVA-пакетов можно синхронизировать между несколькими серверами vCSA (сами шаблоны синхронизировать пока нельзя). Content Library обрабатывает сертификаты и файлы манифеста, входящие в OVA-пакеты в соответствии с лучшими практиками безопасности.
Content Library также нативно поддерживает формат шаблонов VMTX и ассоциирует с ними операции, такие как развертывание ВМ напрямую из Content Library.
8. Функция vSphere Health.
Это новая функциональность vCenter с большим потенциалом. Она позволяет при включенной функции передачи данных CEIP (customer experience improvement program) обрабатывать данные телеметрии виртуальной инфраструктуры на стороне VMware и на основе экспертных алгоритмов вырабатывать рекомендации по ее улучшению. Например, если у вас один Management network, вам могут порекомендовать его задублировать.
В интерфейсе VAMI появилась новая вкладка Firewall, где можно задавать правила сетевого экрана на vCSA (ранее это было доступно только через VAMI API):
Также появилась возможность зайти в VAMI под локальным vSphere SSO аккаунтом, который является членом группы SytemConfiguration.Administrators. Также члены группы Systemonfiguration.BashShellAdministrators могут зайти в шелл VCSA, например, для целей аудита безопасности.
Информация этой заметки не покажется многим из вас новой, но для некоторых может оказаться полезной. Как вы знаете, управляющий компонент VMware vCenter Server сейчас поставляется в двух изданиях vCenter Server, устанавливаемый на платформе Windows, и vCenter Server Appliance (vCSA), представляющий собой готовую к использованию виртуальную машину с сервисами vCenter.
Напомним, что развертывание vCSA уже является опцией по умолчанию, а vCenter для Windows уже не будет присутствовать в следующих версиях VMware vSphere после 6.7.
На данный момент есть 3 издания VMware vCenter:
1. VMware vCenter Essentials
Это издание vCenter недоступно к отдельному заказу. Оно входит в состав изданий vSphere Essentials и vSphere Essentials Plus, которые допускают управление не более чем тремя хостами ESXi (в каждом не более двух физических CPU). Помимо данного ограничения, vCenter Essentials не имеет поддержки таких функций как (детальнее о них - далее):
Enhanced Linked Mode (ELM)
vCenter Server High Availability (VCHA)
vCenter Server File-Based Backup and Restore
vCenter Server Migration Tool
vRealize Orchestrator
vCenter Essentials в составе издания Essentials Plus можно проапгрейдить на vCenter Standard в составе пакета vSphere with Operations Management Acceleration Kit для одного из более высших изданий:
2. VMware vCenter Foundation
Это издание vCenter также не содержит в себе пять перечисленных выше фичей, но позволяет управлять не тремя, а уже четырьмя хостами ESXi с любым числом физических процессоров на борту (ранее число хостов было равно трем, но, начиная с vSphere 6.5 Update 1, его увеличили до четырех). Его можно купить отдельно от лицензий на хосты VMware vSphere / ESXi.
Одна лицензия vCenter Foundation также позволяет создать растянутый кластер из двух площадок, на каждой из которых есть по два хоста ESXi (суммарно под управлением vCenter там находится 4 хоста и Witness VM).
3. VMware vCenter Standard
Это, несмотря на название, самое максимальное издание vCenter. Оно не ограничивает никакую функциональность, то есть в нем доступно управление аж до 2000 хостами ESXi. Здесь вам будут доступны возможности объединения нескольких управляющих серверов Enhanced Linked Mode (ELM), но для каждого из серверов vCenter нужна, само собой, отдельная лицензия Standard.
Также вы сможете производить резервное копирование на уровне файлов (File-Based Backup and Restore) и обеспечивать высокую доступность сервисов vCenter (VCHA) - при этом для нее не нужна дополнительная лицензия на резервный vCenter, хватит одной:
Помимо этого, пользователи vCenter Standard могут применять vCenter Server Migration Tool для миграции с сервисов vCenter для Windows на платформу vCSA. Ну и можно использовать vRealize Orchestrator, который очень пригодится для автоматизации операций в больших инфраструктурах.
Как вы знаете, за прошедшие несколько недель состоялось несколько больших релизов от VMware, вышли обновления как самой платформы виртуализации VMware vSphere 6.7, так и апдейты продуктов VMware Site Recovery Manager 8.1, vRealize Operations 6.7 и других.
Вот суммарно что нового появилось в vSphere 6.7, если постараться уместить это на одну картинку:
Поэтому для многих пользователей VMware vSphere 6.5/6.0/5.5 пришло время большого апгрейда, особенно учитывая, что 19 сентября этого года заканчивается поддержка vSphere 5.5.
Правда не надо забывать, что системы резервного копирования еще не поддерживают vSphere 6.7, но, я думаю, эта ситуация исправится в самом ближайшем будущем. Ну и помните, что напрямую обновиться с vSphere 5.5 на 6.7 не получится, придется делать промежуточный апгрейд на 6.0/6.7:
Поддерживаемые пути апгрейда на vSphere 6.7 включают в себя следующие способы:
Установщик ESXi
Интерфейс ESXCLI
Решение vSphere Update Manager (VUM)
Механизм Auto Deploy
VMware написала в своем блоге интересный пост с рекомендациями по обновлению на vSphere 6.7, приведем оттуда самые важные моменты.
1. Общие рекомендации по платформе vSphere.
vSphere 6.0 - это минимальная версия для апгрейда на vSphere 6.7.
vSphere 6.7 - это последний релиз, который требует ручного указания всех сайтов SSO.
В vSphere 6.7 только TLS 1.2 включен по умолчанию, TLS 1.0 и TLS 1.1 по умолчанию отключены.
Так как структура метаданных томов VMFS6 изменилась, чтобы поддерживать выравнивание по 4K блокам, вы не сможете сделать апгрейд датастора VMFS5 на VMFS6. Это так и осталось со времени vSphere 6.5 (смотрите KB 2147824).
2. Рекомендации по обновлению vCenter.
Развертывание vCenter Server Appliance 6.7 (vCSA) является рекомендуемой конфигурацией.
vCenter Server 6.7 for Windows - это последний релиз для платформы Windows, далее все будет только на базе виртуального модуля.
vCenter Server 6.7 не поддерживает Host profiles с версией ниже 6.0 (см. KB52932).
vCenter Server 6.7 поддерживает работу Enhanced Linked Mode с внедренным компонентом Embedded PSC. Но это поддерживается только для чистых установок, а не апгрейдов. Будьте внимательны!
Если вы используете защиту сервера vCenter в платформе vSphere 6.5 (vCenter High Availability, VCHA), то нужно будет удалить всю конфигурацию VCHA перед проведением апгрейда.
3. Совместимость с другими продуктами VMware.
На момент написания статьи vSphere 6.7 не поддерживала работу со следующими решениями последних версий:
VMware Horizon
VMware NSX
VMware Integrated OpenStack (VIO)
VMware vSphere Integrated Containers (VIC)
Также отметим, что в этой версии vSphere больше нет продукта VMware vSphere Data Protection (VDP), об этом мы писали здесь. Также нотификацию об этом можно увидить на странице сайта VMware, посвященной VDP.
4. Рекомендации по оборудованию.
vSphere 6.7 больше не поддерживает некоторые модели процессоров от AMD и Intel. Их список приведен вот тут, а проверить текущую совместимость можно по этой ссылке.
Следующие CPU пока еще поддерживаются, но их поддержка может быть прекращена в следующей версии:
Intel Xeon E3-1200 (SNB-DT)
Intel Xeon E7-2800/4800/8800 (WSM-EX)
Виртуальные машины, которые совместимы с ESX 3.x и всеми более поздними версиями (начиная с hardware version 4) поддерживаются хостами ESXi 6.7.
Версия железа Hardware version 3 больше не поддерживается.
VM hardware version теперь называется VM Compatibility. Помните, что сначала надо обновить ее на машине до последней версии перед использованием на платформе vSphere 6.7.
Ну а мы со своей стороны рекомендуем всегда делать свежую установку vSphere, если это возможно, а не делать апгрейд, чтобы накопившиеся в прошлом прошлом проблемы вы не унаследовали в новой инсталляции.
На днях компания VMware объявила о выпуске обновленной версии платформы виртуализации VMware vSphere 6.7 (она уже доступна для скачивания). Сегодня мы расскажем о новой версии управляющего сервера VMware vCenter 6.7 и его новых возможностях.
Начать надо с того, что виртуальный модуль VMware vCenter Server Appliance (vCSA) 6.7 теперь рекомендован для развертывания по умолчанию, а значит VMware уже окончательно рекомендует перейти на этот вариант средства управления виртуальной инфраструктурой.
1. Средства управления жизненным циклом.
Об этом мы уже упоминали в статье про vSphere 6.7. Теперь vCenter Server Appliance 6.7 позволяет развернуть vCenter Server с внедренным компонентом Embedded PSC и поддержкой Enhanced Linked Mode. Это дает следующие преимущества:
Теперь для высокой доступности vCSA не нужен балансировщик, и технология vCenter Server High Availability поддерживается нативно.
Теперь проще развертывать инфраструктуру Single Sign-On Domain.
Поддержка максимумов масштабирования vSphere.
Можно делать до 15 развертываний vCSA в рамках одного домена vSphere SSO.
Уменьшение числа узлов, которые надо обслуживать и поддерживать.
Также в составе vSphere 6.7 есть последняя версия vCenter Server 6.7 for Windows, которая уже не будет доступна в следующих версиях платформы. Теперь при миграции старого vCenter на vCSA есть две опции по импорту исторических данных БД:
Развертывание и мгновенный импорт данных
Развертывание и импорт данных в фоновом режиме
При этом показывается примерное время простоя сервисов vCenter во время этих процессов:
Также если вы выбрали импорт данных в бэкграунде, то потом можете поставить этот процесс на паузу. Помимо этого, был улучшен интерфейс процесса миграции, а также появилась возможность выбрать кастомные порты, чтобы не перенастраивать фаервол.
Что касается апгрейда с прошлых версий, то vCenter поддерживает только обновление с vSphere 6.0 и 6.5, а vSphere 5.5 остался в пролете, хотя все еще много пользователей этой версии. Таким клиентам надо будет делать чистую установку или мигрировать сначала на 6.0/6.5 (лучше, все же, ставить заново).
Кстати, помните, что конец поддержки vSphere 5.5 наступает 19 сентября 2018 года.
2. Мониторинг и управление.
В первую очередь надо сказать, что интерфейс инструментария vSphere Appliance Management Interface (VAMI) теперь построен на базе фреймворка Clarity, что делает работу с vCSA простой и приятной:
Теперь при управлении vCSA можно пользоваться отдельным разделом Monitoring для проверки состояния виртуального модуля, а также появилась вкладка Disks, где видны разделы vCSA и их заполненность.
Также появилась вкладка Services, где можно смотреть за состоянием служб vCSA. Кроме этого, были улучшены службы Syslog (теперь можно использовать до трех таргетов), а также Update (теперь можно выбрать патч или апдейт, который будет накатываться). Из VAMI теперь можно отправить патч на стейджинг и потом поставить его, ранее это было доступно только через CLI.
Помимо этого, теперь информация об обновлениях более полная и включает в себя критичность апдейта, требуется ли перезагрузка, что именно внутри и т.п.
Ну и одна из главных ожидаемых возможностей - бэкап сервера vCSA на уровне файлов. Теперь можно задать расписание резервного копирования и сколько резервных копий сохранять:
Помимо бэкапа есть и восстановление, конечно. При этом браузер архивных копий показывает их все, без необходимости искать пути до этих бэкапов.
3. Улучшения vSphere Client.
Теперь в HTML5-клиенте vSphere Client появились обновленные рабочие процессы для следующей функциональности:
vSphere Update Manager
Content Library
vSAN
Storage Policies
Host Profiles
vDS Topology Diagram
Licensing
Но, поскольку vSphere Client не удалось добить до полной функциональности, VMware выпустила и финальный релиз vSphere Web Client 6.7 на базе технологии Flash. Но обещают, что функционал уже почти одинаковый.
Из нового в vSphere Client - появились фичи Platform Services Controller (PSC) UI (/psc), которыми можно управлять через раздел Administration. Кроме этого, появилась отдельная вкладка Certificate management в разделе Configuration.
4. Утилиты CLI.
Вернулась утилита cmsso-util, которая может делать отчеты по виртуальным модулям vCSA, находящимися в рамках одного SSO-домена. Также можно сравнить 2 домена SSO и выгрузить в JSON-файл различия между этими доменами. Кроме этого, можно мигрировать лицензии, тэги, категории и права доступа из одного домена SSO в другой.
Второе улучшение CLI - это установщик vCSA, который позволяет управлять жизненным циклом этого виртуального модуля. vCenter Server Appliance ISO идет вместе с примерами JSON-шаблонов развертывания. Эти шаблоны можно использовать для унификации развертывания серверов vCenter, накатывая эти JSON в пакетном режиме друг за другом. Это позволяет убедиться в унификации конфигурации всех узлов vCenter в рамках больших инсталляций на нескольких площадках.
Скачать платформу VMware vSphere 6.7, содержащую управляющие компоненты VMware vCenter 6.7 и vCSA 6.7 можно по этой ссылке.
Последние версии платформ виртуализации основных вендоров - VMware, Microsoft и OpenStack - фактически сравнялись по своим характеристиками, и сегодня клиент чаще всего выбирает решение не по максимальным характеристикам, а по цене, удобству управления инфраструктурой и различным рискам, в том числе, связанным с поставкой софта в Россию. Мы сделали принципиальный шаг вперёд, чтобы дать клиентам более широкий выбор вендоров при старте нового проекта или просчете рисков продления существующих лицензий. В июле 2017 года был представлен 5nine Manager Datacenter...

 RSS
RSS